- Using the LinkedBST representation you saw in class,
trace through the fourth insert function in the code below.
int main() {
BST<int, string> *dict = new LinkedBST<int, string>();
dict->insert(5, "puppies");
dict->insert(9, "kittens");
dict->insert(11, "foals");
// trace through the following function
dict->insert(10, "calves");
cout << "goodbye!" << endl;
}
- Using separate chaining to resolve hash collisions, insert the following
five items into a hash table of capacity 5, in the order given (from top to
bottom):
| Key | Hash value |
| A | 1 |
| B | 1 |
| C | 1 |
| D | 0 |
| E | 2 |
- Repeat using linear probing to resolve hash collisions, instead of
chaining.
- Consider the following hash function, like the function in hashTable-inl.h:
int hash(int key, int capacity) {
return key % capacity;
}
-
Suppose we have an empty hash table with capacity C. Complete the
following code so that the total running time is asymptotically
proportional to C^2:
HashTable<int,string> ht(); // Created hash table with capacity C.
for (int i = 0; i < C; i++) {
ht.insert(________________, "skittles");
}
- Complete the above code so that the total running time is
asymptotically proportional to n.
(In either case, assume that the hash table does not resize.)
- Consider the following graph:
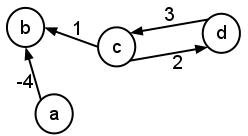
- Give the adjacency-list representation of the graph.
- Give an adjacency-matrix representation of the graph.
- Let G be an undirected graph with an odd number of vertices.
Prove that G contains at least one vertex with an even degree.
- Play Charlie Garrod's
Dijkstra Adventure Game by running dag in a terminal
window. Be sure to play once or twice with the --random option:
$ dag --random
(We're sorry for how tedious the game can be -- the graph is big!)
- Below is a recursive version of depth-first search.
Recursive DFS is extremely simple and elegant if the
algorithm does not need to track additional information or return
any value:
dfs(G, src): // This function initializes the
isVisited = new dictionary // dictionary and calls the
for each vertex v in G: // recursive helper function.
isVisited[v] = false
recursiveDfs(G, src, isVisited)
recursiveDfs(G, src, isVisited): // This recursive function
isVisited[src] = true // searches the graph.
for each neighbor v of src:
if !isVisited[v]:
recursiveDfs(G, v, isVisited)
- Execute dfs on the following graph, using s as the source
vertex. Draw the stack diagram for the program as it
executes. (Assume that isVisited refers to a single copy of the
dictionary for all frames of the stack.)
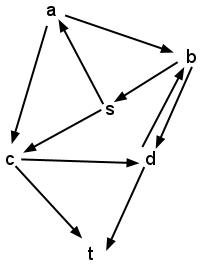
- Modify the pseudocode above to accept a second vertex, dest, as
an argument. Return true if there is a path from src->dest in G,
and return false otherwise.
- Modify the pseudocode again to return the length of some
src->dest path (not necessarily the shortest path) if there is a
path from src to dest in G. If there is no src->dest path, return
-1.
- Write a version of breadth first search and depth first search
that determines if a graph is connected.
- Compare the run time of all key Graph methods using an adjacency list
versus adjacency matrix representation. Express each in terms of the number
of vertices (n) and edges (m) in the graph.
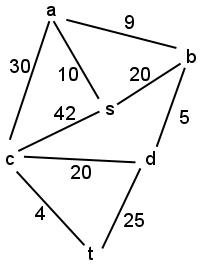
- Execute Prim's algorithm to find a MST of the following graph using
s as the initial vertex. For each step of the algorithm, show
which edges and vertices have been selected for the MST up to that step.
- What is the run time of breadth first search? depth first search?
Dijkstra's Algorithm?