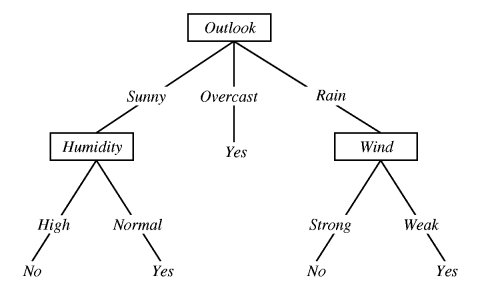
- binaryData.py: The target attribute of each example is the output of a simple function based on three bits. Contains the two examples we discussed in class (binaryA: either the first or second bit is on; binaryB: the first and third bit are equal).
- tennisData.py: The target attribute of each example is whether or not to play tennis based on the weather conditions that day.
- votingData.py: The target attribute of
each example gives the political part of the representative (either
democrat or republican), and the remaining attributes indicate his or
her vote for each bill considered by Congress (y for a "yea"
vote, n for a "nay" vote, and ? for an unknown vote
or abstention). Source: Congressional Quarterly Almanac, 98th
Congress, 2nd session 1984, Volume XL: Congressional Quarterly Inc.
Washington, DC, 1985. The names of the attributes along with a short
description are shown below:
Attribute Short Description feeFreeze physician fee freeze testBan anti-satellite test ban exports duty-free exports superfund superfund right to sue immigration immigration elSalvador aid to El Salvador southAfrica export administration act South Africa crime crime contras aid to Nicaraguan Contras budget adoption of the budget resolution missile mx missile water water project cost sharing religion religious groups in schools synFuels synthetic fuels corporation cutback infants handicapped infants education education spending