Lab 1: Building a Buffer Manager
Due by 11:59 p.m., Monday, September 24, 2018.
This is a partnered lab. You are to complete this lab with one other person, who must attend the same lab as you. You may discuss the lab concepts with other classmates. Please use Teammaker to set your lab partner preferences. You can choose “Random” if you do not have a partner. Remember the Academic Integrity Policy: do not show your code/solution to anyone outside of the course staff and your lab partner. Do not look at any other group’s code/solution for this lab (current or past). If you need help, please post on Piazza.
- Overview
- The WiscDB I/O Layer
- The Buffer Manager
- Implementing the Buffer Manager
- Coding and Testing
- Acknowledgements
- Submitting your lab
Overview
The goal of the WiscDB projects is to allow students to learn about the internals of a data processing engine. In this first assignment, you will build a buffer manager on top of an I/O Layer that I provide. Future labs will add additional layers to the DB code.
The code base is quite extensive and will require much reading of API documentation and thorough testing. You are responsible for making significant progress early on; waiting until the last few days will not be manageable. The goals of this assignment include:
- Understanding the duties of the Buffer Management layer of a database
- Simulating the management of main memory and an appropriate replacement policy
- Navigating provided documentation to utilize a provided interface for the disk I/O layer.
- Using formal commenting/documentation techniques (Doxygen) to create a clear, understandable code base.
- Developing a testing strategy for a large, intricate system.
Getting Started
Click to expand
Both you and your partner will share a repo named Lab1-userID1-userID2. Note that the lab will not release until you have both marked your partner preferences on Teammaker. You should find your repo on the GitHub server for our class: CPSC44-F18
Clone your Lab 1 git repo containing starting point files into your labs directory that you created last week:
cd ~/cs44/labs
git clone [the ssh url to your your repo]
cd Lab1-userID1-userID2
If you need help, see the instructions on Using Git (follow the instructions for repos on Swarthmore’s GitHub Enterprise server). If all was successful, you should see the following files (highlighted files require modification):
Makefile- Use for building your program. You may edit this file to add extra source files or execution commands for test programs you create.buffer.h/.cpp- You must edit these files to implement theBufferManagerand relatedFrameclass. The header file has been completed for you.bufferHashTable.h/.cpp- Defines theBufferHashTableclass which maps pages to frames in the buffer pool for quick reference. You must complete the implementation for the provided definition.main.cpp- The provided code demonstrates usage of thePageandFileclasses. In addition, there are several very basic tests for the buffer manager. You must comment these tests and augment them to thoroughly test your buffer manager.README- a few wrap-up questions for you to answer about the lab assignment.
In addition, you should run make setup (just once) to create symlinks to shared libraries (do not copy these to your directory) that are needed for your programs to run:
cd ~cs44/Lab1-userID1-userID2/
make setup
include/- contains header files for thePage,Fileand related classes. These cannot be modified, but you can open the header files to see their contents. Each class must be well understood to manage the interface to the I/O layer. While reading the header files may be helpful, you should start with the online WiscDB documents first.lib/- necessary object files. The contents of this directory can be ignored (plus one for abstraction).exceptions/- defines the list of possible exceptions for WiscDB. You will need to reference these exceptions to both handle possible errors that can be thrown to you or that you must throw. Again, it is probably easier to refer to the online documentation.
The WiscDB I/O Layer
The lowest layer of the WiscDB database systems is the I/O layer. This layer allows the upper level of the system to:
- create/destroy files
- allocate/deallocate pages within a file
- insert/retrieve/update records within a page
- read and write pages of a file
This layer consists of two classes: a File class and a
Page class. These classes use C++ exceptions to handle the occurrence of any unexpected event.
Implementation of the File class, the Page class, and the exception classes have been provided for you including extensive documentation. In many cases you will need to respond to exceptions to complete your implementation below.
Before reading further you should first read the documentation that describes the I/O layer of WiscDB so that you understand its capabilities. In a nutshell the I/O layer provides an object-oriented interface to the Unix file system with methods to open and close files and to read/write pages of a file. You will utilize these methods to move pages into the buffer pool and higher-level methods (e.g., main.cpp to process a query).
Below and in the given code, you will see the customed-defined types FrameId and PageId. Practically speaking, these are both int (unsigned and thus non-negative). Using these defined types makes your code more readable. You know a variable declared FrameId will be an index into a Frame table, and PageId refers to a page number in a file.
The Buffer Manager
A database buffer pool is an array of fixed-sized memory buffers called frames that are used to hold database pages (or blocks) that have been read from disk into memory. A page is the unit of transfer between the disk and the buffer pool residing in main memory. Most modern database systems use a page size of at least 8KB (8,192 bytes). Another important thing to note is that a database page in memory is an exact copy of the corresponding page on disk when it is first read in. Once a page has been read from disk to the buffer pool, the DBMS software can update information stored on the page, causing the copy in the buffer pool to be different from the copy on disk (which is now outdated). Such pages are termed dirty.
Since the database on disk itself is often larger than the amount of main memory that is available for the buffer pool, only a subset of the database pages fit in memory at any given time. The buffer manager is used to control which pages are memory resident. Whenever the buffer manager receives a request for a data page, the buffer manager checks to see if the requested page is already in the buffer pool. If so, the buffer manager simply returns a pointer to the page. If not, the buffer manager frees a frame by evicting an old page (and possibly by writing it to disk if it is dirty) and then loads the requested page from disk into the newly available frame. The algorithm for determining the page to evict is known as the replacement policy.
Buffer Replacement Policy using the Clock Algorithm
There are many ways of deciding which page to replace when a free frame is needed. Commonly used policies in operating systems are FIFO (first in first out), MRU (most recently used), and LRU (least recently used). LRU, arguably the most useful policy, suffers from high overhead costs due to the need for a priority queue. An alternative approach, the circular array buffer, or clock algorithm, approximates LRU behavior with much better run time performance.
First, some terminology:
- A
Frameholds a page from disk, and maintains metadata for the page it holds (if any) numFramesis the size of the buffer pool (the number of pages we can hold in memory)- A
validframe is one that holds an actual page from disk (i.e., an emptyFrame[#frame] is notvalid). - A
pinnedpage is one that is actively claimed (i.e., being used) by an application. Having 0 pins means the page in a frame is not being used. - A
dirtypage is a page in the buffer pool that has been written to while in memory, but not yet flushed to disk (i.e., it is more current than the disk version). - A
refbitis particular to the clock algorithm and denotes that aFramehas been unpinned for a whole clock cycle.
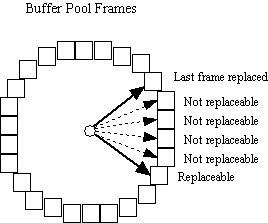
The image to the left shows the conceptual idea of the clock array. Each square box corresponds to a frame in the buffer pool. Assume that the buffer pool contains numFrames frames, numbered 0 to numFrames-1.
We can imagine all the frames in the buffer pool are arranged in a circular list.
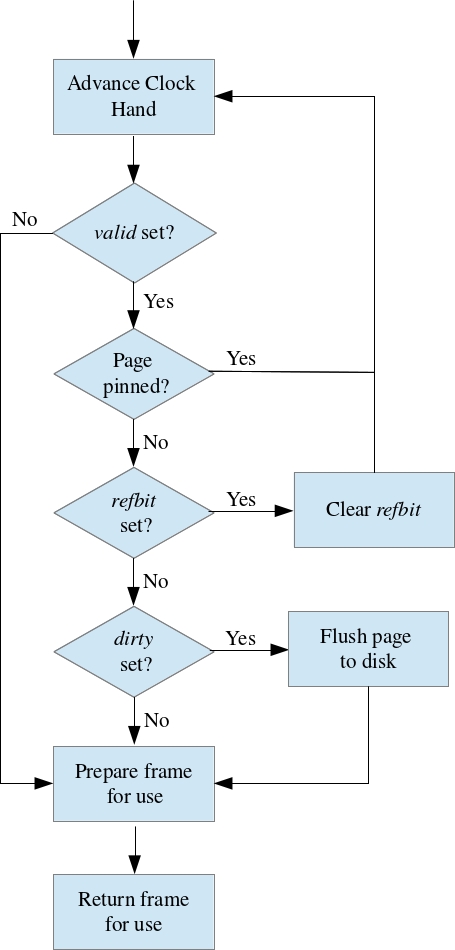
The algorithm is depicted in the flow chart to the right. At any point in time the clock hand (an integer whose value is between 0 and numFrames-1) is advanced in a clockwise fashion. If a frame is unoccupied (i.e., the page is not valid), it is an obvious candidate for replacement.
Otherwise, we check to see if the page is still pinned since we do not want to remove a page from the pool that is still being used. If a page is not in use, we refer to the refbit to approximate our LRU algorithm. If the refbit is true, the page has been recently unpinned and gets a
“free pass” (i.e, set the bit to false and move on). Otherwise, we have found a replacement. If the selected buffer frame is dirty, the page currently occupying the frame is written back to disk. Regardless, the frame is cleared and the requested page from disk is read in to the freed frame. Further details are available below.
Implementing the Buffer Manager
The WiscDB buffer manager uses three C++ classes that you will implement:
BufferManager- the buffer pool. A DBMS has one instance of the buffer manager, which maintains all pages (and their frames) in memory.Frame- maintains the metadata for aPagein memory. TheBufferManagerwill maintain an array ofnumFramesFrameobjects.BufferHashTable- a helper data structure to make it easy to find which pages are currently in the buffer pool and which are not. It will only be used within theBufferManagerclass.
Buffer Hash Table
The BufferHashTable class is used to map a particular page to a buffer pool frame (if it is in memory) and is implemented using separate chaining. You must complete this implementation using the
provided class definition in bufferHashTable.h.
struct HashItem
Click to see HashItem definition (from bufferHashTable.h)
/**
* @brief Declarations for buffer pool hash table item
*/
struct HashItem {
/**
* pointer a file object (more on this below)
*/
File *file;
/**
* page number within a file
*/
PageId pageNo;
/**
* frame number of page in the buffer pool
*/
FrameId frameNo;
/**
* Next node in the hash table for separate chaining
*/
HashItem* next;
};
The key structure is a HashItem (API), which maintains one item in the hash table, similar to a node in a linked list. It maintains the following data:
next: a pointer to point to the nextHashItemin the chain.frameNo: aFrameIdto locate the page in the buffer pool.file: a pointer to theFilethe page is frompageNo: the page number (PageId) in the file.
The file and pageNo uniquely identify a Page (i.e., they form the key) while the frameNo is the value to be returned. You do not need to modify this struct.
class BufferHashTable
Click to see definition from bufferHashTable.h
/**
* @brief Hash table class to keep track of pages in the buffer pool
*/
class BufferHashTable
{
private:
/**
* Size of Hash Table
*/
int SIZE;
/**
* Actual Hash table (array of HashItem chains)
*/
HashItem** table;
/**
* returns hash value between 0 and SIZE-1 computed using file and pageNo
*
* @param file File object
* @param pageNo Page number in the file
* @return Hash value.
*/
int hash(const File* file, const PageId pageNo);
public:
/**
* Constructor of BufferHashTable class
*/
BufferHashTable(const int htSize);
/**
* Destructor of BufferHashTable class
*/
~BufferHashTable();
/**
* Insert entry into hash table. Maps (file, pageNo) to bucket and
* inserts a HashItem.
*
* @param file File object
* @param pageNo Page number in the file
* @param frameNo Frame number assigned to that page of the file
* @throws HashAlreadyPresentException if the corresponding file/page
* already exists in the hash table
*/
void insert(File* file, const PageId pageNo, const FrameId frameNo);
/**
* Check if (file, pageNo) is currently in the buffer pool (ie. in
* the hash table). Returns frame number of location in pool
*
* @param file File object
* @param pageNo Page number in the file
* @param frameNo Frame number reference containing the result of lookup
* @throws HashNotFoundException if the file/page entry is not found in the
* hash table
*/
void lookup(const File* file, const PageId pageNo, FrameId &frameNo);
/**
* Remove (file,pageNo) the buffer pool by deleting the appropriate
* item from hash table.
*
* @param file File object
* @param pageNo Page number in the file
* @throws HashNotFoundException if the file/page entry is not found in the
* hash table
*/
void remove(const File* file, const PageId pageNo);
};
The BufferHashTable(API) is where the hash table is defined. You have been provided a method do compute the hash key as well as the constructor, which initializes your array of HashItem chains. Do not modify either method, but instead read and understand how they work.
You will
need to complete the implementation for the destructor, insert(), lookup(),
and remove() methods as explained in the documentation (equivalently provided in the header file, in the collapsed link above, and in the online documentation linked to for each function above).
- The destructor should march through each bucket, deleting all
HashItemobjects in each chain before deleting the table. - For the other methods, pay attention to corner cases (e.g., empty chains) and thoroughly test your class (historically, this class is the simplest to implement but the source of many bugs).
- You will need to both
throwand handle exceptions. For example,insert()shouldthrowaHashAlreadyPresentExceptionif the method was erroneously called for a page already in the table. See the section on exceptions below for a reminder on how to use exceptions. insert()should follow these high-level steps:- determine if the page is already in the table, throwing an exception if so.
- assuming the page does not exist, create a
HashItemto contain the new item. Set theHashItemdata using the given parameters. - use the given
hashfunction to determine which bucket (i.e., index into the table) the new item belongs. - insert the newly created
HashItemat the beginning of the chain and have it point to the previous head of the chain.
- You will need to determine the steps for the other two methods. Both should throw a
HashNotFoundExceptionif the given (file,pageNo) combination are not in the table.
Frame
Click to see definition from buffer.h
/**
* @brief Maintains information about one buffer pool frame. One frame
* corresponds to one page on disk.
*/
class Frame {
friend class BufferManager;
private:
/**
* Pointer to file the Page belongs to.
*/
File* file;
/**
* Page number within file to which corresponding frame is assigned
*/
PageId pageNo;
/**
* Frame number of the frame in the buffer pool
*/
FrameId frameNo;
/**
* Number of times this page has been pinned
*/
int pinCnt;
/**
* True if page is dirty; false otherwise
*/
bool dirty;
/**
* True if page is valid (i.e., frame is in use)
*/
bool valid;
/**
* Has this buffer frame been reference recently
*/
bool refbit;
/**
* Initialize buffer frame to an empty state
*/
void reset();
/**
* This method is called when a frame has been assigned to a page using
* readPage() or allocatePage() in the BufferManager. Member variables
* are set correspondingly to a newly loaded page.
*
* @param filePtr File object
* @param pageNum Page number in the file
*/
void load(File* filePtr, PageId pageNum);
void print();
/**
* Constructor of Frame class
*/
Frame();
};
Each Frame (API) stores metadata about a Page object in the buffer pool:
pageNoand thefilepointer uniquely identify the page, as is the case in theBufferHashTable.frameNois the index of thisFrameinstance in the buffer pool.- The remaining meta data is as defined in the clock algorithm.
- The
BufferManageris declared afriend; in practical terms, that means that when you implement theBufferManager, you can directly access the private data members of theFrameclass (no need to implement getters).
You you will need to implement the basic methods
of the class (i.e., reset() and load()), just to ensure you
understand how to use the class. reset() is invoked when a Frame is
emptied and should reset all class variables to a default state:
- Use the pre-defined constant for an invalid
pageNo(Page::INVALID_NUMBERas defined in thePageclass). - The
FrameIdshould only be modified by theBufferManager. - A default frame is not dirty or valid and there are no pins.
- The reference bit only matters when a page is loaded into the frame.
load() is invoked after a page has been assigned to a frame; this
method should set all member variables appropriately. This method is
utilized for a new Page being loaded into the frame. A newly loaded page is not dirty, but the frame is now valid. You may want to set the pin count to 1, but we recommend doing this in the buffer manager methods that call load() (i.e., allocatePage() and readPage()). Instead, initialize the pin count to 0.
BufferManager
The BufferManager (API) class is the heart of the buffer manager (and this assignment). At a high level, the BufferManager manages a buffer pool of frames that contain pages that get loaded from and sent back to disk.
Data members
Click to see data members from buffer.h
/**
* @brief The central class which manages the buffer pool including frame
* allocation and deallocation to pages in the file
*/
class BufferManager
{
private:
/**
* Current position of clockhand in our buffer pool. The clock hand is a
* FrameId from 0 to numFrames-1
*/
FrameId clockHand;
/**
* Number of frames in the buffer pool
*/
std::uint32_t numFrames;
/**
* Hash table mapping (File, page) to a FrameId
*/
BufferHashTable *hashTable;
/**
* Array of Frame objects to hold information corresponding to every
* frame allocation from the buffer pool
*/
Frame *frameTable;
public:
/**
* Actual buffer pool of Pages. A table of Page objects, with each
* index corresponding to Frame at the same index of frameTable.
*/
Page* bufPool;
- There are two arrays:
bufPool(an array ofPageobjects) andframeTable(an array ofFrameobjects). These are parallel arrays; the frame at a particular index offrameTablestores the metadata for thePagestored at the same index in thebufPoolarray. hashTableis a dictionary that you use to find a particular page in the pool quickly. When checking the status of a certainPageobject, we first obtain it’sFrameIdby looking it up in the hash table, and then use the obtainedFrameIdto index intoframeTableto get theFramemetadata and the same index intobufPoolto get thePageitself. Note that we also use the hash table to quickly determine that aPageis not in the pool and needs to be added.clockHandis the current position of hand in the clock algorithm (i.e., index into the parallel arrays).
Class Methods
Click to see method declarations from buffer.h
private:
/**
* Advance clock to next frame in the buffer pool
*/
void advanceClock();
/**
* 'Allocate' a free frame; employs the clock replacement policy to identify
* and free a frame for loading a page from disk
*
* @param frame frameID of allocated frame is returned
* via this variable
* @throws BufferExceededException If no such buffer frame is found which
* can be allocated
*/
void allocateFrame(FrameId & frame);
public:
/**
* Constructor of BufferManager class
*/
BufferManager(std::uint32_t bufs);
/**
* Destructor of BufferManager class
*/
~BufferManager();
/**
* Reads the given page from the file into a frame and returns the pointer
* to page. If the requested page is already present in the buffer pool, its
* pin count is increased and a pointer to that frame is returned; otherwise
* a new frame is allocated from the buffer pool for reading the page.
*
* @param file File object
* @param PageNo Page number in the file to be read
* @param page Reference to page pointer. Used to fetch the Page object
* in which requested page from file is read in.
*/
void readPage(File* file, const PageId PageNo, Page*& page);
/**
* Unpin a page from memory when one requesting application
* no longer requires it to remain in memory. Decrements pin count and sets
* refbit if pin count is now zero.
*
* @param file File object
* @param PageNo Page number
* @param dirty True if the page to be unpinned needs to be marked dirty
* @throws PageNotPinnedException If the page is not already pinned
*/
void unPinPage(File* file, const PageId PageNo, const bool dirty);
/**
* Allocates a new, empty page in the file and returns the Page object.
* The newly allocated page is also assigned a new frame in the buffer pool.
*
* @param file File object
* @param PageNo Page number. The number assigned to the page in the file
* is returned via this reference.
* @param page Reference to page pointer. The newly allocated in-memory
* Page object is returned via this reference.
*/
void allocatePage(File* file, PageId &PageNo, Page*& page);
/**
* Writes out all dirty pages of the file to disk.
* All the frames assigned to the file need to be unpinned from buffer pool
* before this function can be successfully called.
* Otherwise an exception is thrown.
*
* @param file File object to flush to disk
* @throws PagePinnedException If any page of the file is pinned in the
* buffer pool
* @throws BadBufferException If any frame allocated to the file is found
* to be invalid
*/
void flushFile(const File* file);
/**
* Delete page from file and also from buffer pool if present.
* Since the page is entirely deleted from file, its unnecessary to see if
* the page is dirty.
*
* @param file File object
* @param PageNo Page number
*/
void disposePage(File* file, const PageId PageNo);
/**
* Print member variable values.
*/
void printSelf();
BufferManager(std::uint32_t bufs)
This is the class constructor and has been provided. The constructor allocates an array for the buffer pool withnumFramespages and a correspondingFrametable. AllFrames will be in the reset state and the hash table is created and initially empty.~BufferManager()
Flushes out all dirty pages and deallocates all dynamically allocated class data. Any memory allocated inBufferManagermethods (including the constructor) should be deleted here.void advanceClock()
Advance clock to the next frame in the buffer pool.void allocateFrame(FrameId& frame)
Allocates a free frame using the clock algorithm and, if necessary, writing a dirty page back to disk. ThrowsBufferExceededExceptionif all buffer frames are pinned. This private method will get called by thereadPage()andallocatePage()methods described below. Make sure that if the buffer frame allocated has a valid page in it, you remove the appropriate entry from the hash table.-
void readPage(File* file, const PageId PageNo, Page*& page)
There are two cases to be handled: the page is already in main memory or it is not. Use your hash table to help decide which is the case and then handle both scenarios. See the section below on exceptions for how to use atry/catchblock to implement these two scenarios:Case 1: The specified page is not already in the buffer pool. You will need to find a buffer frame (i.e., call
allocateFrame()) and then load the specified page from disk (i.e.,file->readPage(PageId)). Be sure to fully update the buffer pool meta-data, including insert the page into the hash table, storing the page in the buffer pool, and invokingload()on the frame to set it up properly. Return a pointer to the page now stored in the buffer pool via thepageparameter e.g.,page = &bufPool[index];Case 2: the specified page is in the buffer pool. In this case, you simply need to update the pin count for the frame, and then return a pointer to the page stored in the buffer pool via the
pageparameter. void unPinPage(File* file, const PageId PageNo, const bool dirty)
When a higher-level query no longer needs a page, it releases its pin on the page. The buffer manager decrements the pin count of the frame holding the given page. If the pin count hits 0, you should set therefbit. The input parameterdirtyindicates whether the page was modified and should correspondingly set thedirtybit for the frame totrueif it was modified. Note that once dirty, a page stays dirty until it is flushed to disk, so do not set the dirty bit to false here. The method should throwPageNotPinnedExceptionif the pin count is already 0. The method should allow the hash table to throw an exception if the page is not in the hash table (this is done bylookup()in theBufferHashTable, just ensure you do notcatchthat exception here).void allocatePage(File* file, PageId& PageNo, Page*& page)
This method asks the buffer manager to handle a low-level disk allocation of space to hold a page. It should first rely on theFileinterface to handle the actual disk allocation (seeallocatePage()in theFile) class. In addition to allocating a page on disk, the buffer manager must place this new page in the buffer pool (similar to Case 1 forreadPageabove). The method returns both the page number of the newly allocated page (see thePageinterface to determine how to retrieve this) and a pointer to the page itself.void disposePage(File* file, const PageId pageNo)
This method deletes a particular page from file. Before deleting the page from file, make sure that if the page to be deleted is in the buffer pool, that frame is emptied and correspondingly entry from hash table is also removed.void flushFile(File* file)
When a query is completely done with using a file (e.g., did a full scan of all records), it may choose to tell the buffer manager that the file is no longer needed. This method should scan the buffer pool for pages belonging to the file. For each page encountered it should:- write dirty pages to disk
- remove the page from the hash table (whether the page is clean or dirty)
- empty (i.e., reset) the
Frameholding the page in the buffer pool
This method should not boot pinned pages, and should throw a
PagePinnedExceptionif some page of the file is pinned to indicate the method was not used correctly. It should throw aBadBufferExceptionif an invalid page belonging to the file is encountered (this probably should not happen, but should be checked as a possible buggy state).
Coding and Testing
Keep these style and testing guidelines in mind:
- We have defined this project so that you can understand and reap the full benefits of object-oriented programming using C++. Your coding style should continue this by having well-defined classes and clean interfaces.
- The code should be well-documented, using Doxygen style comments. Each function should be preceded by a few lines of comments describing the function and explaining the input and output parameters and return values.
- Each file you are assigned to modify should start with your names and student ids, and should explain the purpose of the file.
- Search for
TODOstatements in the documents for help navigating implementation requirements. Remember to delete this when “DO” them. - You should thoroughly test your program. This includes adding
tests to main.cpp. You can also add your own main program with test code (you are not required to do so, but it is recommended). If you do, you will need to update the
Makefileto process each test file separately - see theMakefilecomments for suggestions on how to do this. - The tests I have provided are not designed to pinpoint specific errors. They are not very useful as debugging tools - you should add private methods, print statements, and gdb sessions to augment the tests.
- The tests I have provided are not exhaustive of all requirements. You should add harder tests for requirements not covered. We will test your programs on several held-aside test cases, you should try to anticipate and design these tests yourselves.
- With all implementations, you are allowed and encouraged to add private methods. However, you are forbidden from adding data members, public methods, and/or changing the access of provided data and methods.
Exceptions
The documentation in several places calls for you to explicitly invoke exceptions if certain conditions are met. You will do this by using the throw command. For example, the insert() function of the BufferHashTable has you throw a HashAlreadyPresentException if the page is already in the table:
if (CONDITION){ //page already in table
throw HashAlreadyPresentException(FILENAME, PAGENUMBER, 0);
}
You need to fill in the CONDITION, FILENAME, and PAGENUMBER. Pay attention to all methods in this lab; it will be clearly stated when you need to throw an exception.
In some cases, you need to resolve exceptions that may be used to signal an event (as opposed to a fatal error). In this case, you should use a try-catch block:
try{
//insert code that could potentially cause an exception
} catch (Exception &except){ //Change Exception to the specific exception name
//respond to exception
}
//common code that occurs regardless of whether exception was hit or not
For example, when asked to read a page to the buffer pool (i.e., BufferManager::readPage()) you first need to use BufferHashTable::lookup() to see if the page is already in the pool. If it isn’t, you should anticipate lookup() to throw a HashNotFoundException:
try{
hashTable->lookup(...);
//this code only runs if lookup successfully found the page
//TODO: insert code for a page already in the buffer pool
} catch (HashNotFoundException &e){
//this block only runs if lookup failed to find the page in the pool
//TODO: add page to the pool
}
//This code runs regardless of what happens above
//TODO: insert code that is common to the scenarios above
Acknowledgements
Much of the code base was provided and developed by the University of Wisconsin Database Group.
Submitting your lab
Before the due date, push your solution to github from one of your local repos to the GitHub remote repo. Only one of you or your partner needs to do this.
From your local repo (in your ~cs44/labs/Lab1-userID1-userID2subdirectory)
make clean
git add *
git commit -m "our correct, robust, and well commented solution for grading"
git push
If that doesn’t work, take a look at the “Troubleshooting” section of the Using Git page.
Also, be sure to complete the README.md file, add and push it.