HW 1: Disk & Buffer Manager; ER & Relational Design
Due by 11:59 p.m., Saturday, October 6, 2018.
This is a partnered lab. You are to complete this lab with one other person, who must attend the same lab as you. You may discuss the lab concepts with other classmates. Please use Teammaker to set your lab partner preferences. You can choose “Random” if you do not have a partner. Remember the Academic Integrity Policy: do not show your code/solution to anyone outside of the course staff and your lab partner. Do not look at any other group’s code/solution for this lab (current or past). If you need help, please post on Piazza.
- Overview
- Getting Started
- Disk and Buffer Manager
- ER Models
- Relational Models
- SQLite
- Submitting your lab
Overview
This assignment is a problem set that will engage the few first modules of the semester. The goals of his lab are to:
- Analyze aspects of the disk and buffer managers
- Design an ER model from a description of data and its use.
- Translate an ER model to a Relational model
- Define relations and constraints in SQL
- Get some practice using sqllite
While you will work with a partner, you are not allowed to divide and conquer this assignment with your lab partner. Each individual must work on each of the problems below - this is in your best interest as these problem sets closely mimic questions you will see on exams. I suggest two strategies (which can be intermixed):
-
Work together from the start. Find meeting times that allow you and your partner to start and continue to make progress on each question.
-
Work individually to start, then meet and discuss. Each individual answers the questions below, then meet and identify disagreements or confusions. Just be sure both individuals have answer the questions separately before meeting.
Getting Started
Both you and your partner will share a repo named Homework1-userID1-userID2. Note that the lab will not release until you have both marked your partner preferences on Teammaker. You should find your repo on the GitHub server for our class: CPSC44-F18
Clone your Homework 1 git repo containing starting point files into your labs directory that you created last week:
cd ~/cs44/labs
git clone [the ssh url to your your repo]
cd Homework1-userID1-userID2
If you need help, see the instructions on Using Git (follow the instructions for repos on Swarthmore’s GitHub Enterprise server).
If all was successful, you should see the following files (highlighted files require modification):
README- a few wrap-up questions for you to answer about the lab assignment.hw1.tex- LaTeX file for you to type your solution
In addition, you should add the following file after you complete the last portion:
restaurant.db- SQLite database filehw1.pdf- Solution for the problems below. Hard copies will not be accepted. LaTeX is strongly encouraged to ensure your solutions are legible.
You should submit your solution as a PDF and by using LaTeX. If you are not familiar with LaTeX, here is a primer. You may ask your classmates any questions about LaTeX without worrying about violating the academic integrity policy. To create a pdf, you can use pdflatex and open the pdf with your preferred viewer (e.g., acroread):
$ pdflatex hw1.tex
$ acroread hw1.pdf
Disk and Buffer Manager
-
Exercise 9.4, Ramakrishnan and Gehrke
-
Consider a hybrid love/hate replacement policy. The policy tries to identify future needs be getting a hint from the upper level layers about the page. When a page is unpinned, the upper level call indicates that the page is loved if it is likely that the page will be needed in the future, and is hated (or, not loved) if it is likely that the page will not be needed. This is similar to how a page is marked dirty by the upper-level caller in Lab 1.
The policy maintains an MRU list for the hated pages and an LRU list for the loved pages. In case of multiple applications using a page, we will go with “love conquers hate”, meaning that once a page is indicated as loved it should remain loved (again, similar to how we set the dirty bit in Lab 1).
Answer the following questions in 1-2 sentences each:
A. How would an upper-level process use this buffer policy to avoid sequential flooding? Your answer should identify (a) what type of access leads to sequential flooding and (b) what designation of love/hate the process would give when unpinning a page.
B. Assume we utilize a priority queue for LRU (with least-recently unpinned pages at the front) and a separate PQ for MRU (with most-recently unpinned pages at the front). Provide concise pseudocode for your replacement algorithm (i.e.,
allocateFrame()). You need to succinctly describe the major steps in finding an available frame, you do not need to worry about handling dirty bits, resetting frames, or updating the hash table. Your pseudocode should only be a few lines long. -
Refer to the textbook to refresh your understanding of the LRU, Clock, and MRU strategies. Assume you are given a buffer manager with 4 frames (all empty to start). Below, I have given a series of page requests where each row indicates a time step and the page that is read from disk at that time. Each step involves reading and then immediately unpinning the page before the next step.
Simulate all three replacement policies, independently, on this sequence. For each policy provide:
A. a list of all pages as they get evicted from the buffer pool, as well as the time that that they were removed. For example: LRU: (5,B), (8,A) indicates that the LRU policy evicted page B at time step 5 and page A at time step 8 (and no other replacements occurred).
B. the state of all relevant meta-data after time-step 8. This includes which pages are in the buffer pool. For the clock algorithm, provide the value of the refbit (
Trueor 1 indicates that the free pass has already been taken) and the clock hand; for LRU and MRU, provide the priority queue with the next-to-be-removed page at the front.Time Step 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Page A B C D A A B E F A G B A B C G
ER Models
-
You have been tasked with modeling the book industry. Draw an ER diagram to model the following: you want to keep track of books, authors, and bookstores. Books need to have titles, unique ISBNs, and a genre. Authors have unique SSNs, names, and a phone number. Bookstores have a store id, address, and name. We would also like to keep track of citations (where one book references another), the author’s of a book (each book must have at least one author), and what books a store sells. NOTE: there are many tools for drawing ER diagrams; I recommend draw.io.
-
As a separate problem, we would like to keep track of all book sales. Books have the same attribute above, and for each we keep track of its transactions (i.e., daily sales). Each transaction has a date and quantity, neither of which is unique. But each book only has one daily entry. Draw the corresponding diagram.
-
Lastly, in this modern age, our database should keep track of whether a book is electronic or physical. Draw a diagram for books (which have similar attributes as above); in addition, electronic books have a file size and physical books have a weight. Also, we would like to note relationships between electronic books and the platforms they can be used on. Platforms include a company and webpage (unique). Electronic books are limited to at most one platform. You do not need to model any other requirements from the previous two problems.
Relational Models
-
Briefly, explain how views can provide logical data independence.
-
Translate Figure 2.18 into a relational schema. You do not have to use SQL, but it should be clear what the attributes are and which are primary keys. Also, explicitly identify foreign key references.
-
Exercise 3.8 Parts 1,3,4 only, Ramakrishnan and Gehrke
-
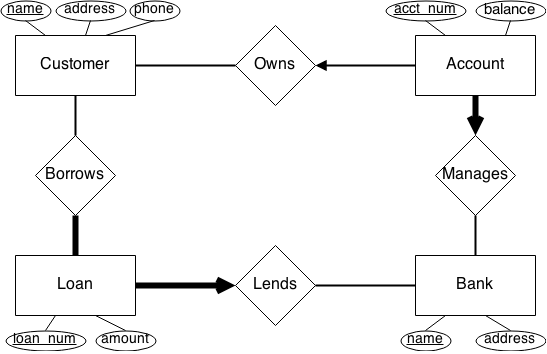
Consider the ER diagram below which we wish to convert to a relational model. Which, if any, of the relationship constraints are not possible to incorporate into the relational model? Briefly explain.
SQLite
Building off the SQLite tutorial from Week 4 lab, we you will construct and submit restaurant.db, a database modeling the restaurant industry.
First, create your database:
sqlite3 restaurant.db
Note: if you need to start over, you can always quit sqlite and delete your previous database:
sqlite> .exit
$ rm restaurant.db
-
Create a new database with following relations (make reasonable guesses as the types of different fields):
- Customer(id, name, budget)
- Restaurant(id, name, address)
- DinesAt(custid, restid, date)
List the schema in sqlite to verify that you have correctly created these relations.
-
Add instances to your database. Add 8 Customer instances, 3 Restaurant instances, and make sure that each customer you add dines at some restaurant. You may choose any values for the relation instance attributes that you’d like, so long as they satisfy the given constraints.
I recommend that you use bulk loading from files for this part. Create an ascii file for each relation, each containing relation instances. Then try bulk loading them into your
restaurant.dbdatabase. You could also runINSERT INTOSQL statements to add values in one at a time.Run
SELECTqueries to list the relation instances from each relation to verify that you have correctly added your data. -
I will run the following query on your resulting database:
SELECT C.name, R.name FROM Customer C, Restaurant R, DinesAt D WHERE C.id = D.custid AND R.id = D.restid;It should produce a result relation consisting of the name of each customer and the name of the restaurant in which they dine.
-
Add your database to your lab repo submission:
git add restaurant.db git commit -m "commit message" git push
Submitting your lab
Before the due date, push your solution to github from one of your local repos to the GitHub remote repo. Only one of you or your partner needs to do this.
From your local repo (in your ~cs44/labs/Homework1-userID1-userID2 subdirectory)
git add hw1.tex hw1.pdf restaurant.db README.md
git commit -m "our solution"
git push
If that doesn’t work, take a look at the “Troubleshooting” section of the Using Git page.
Also, be sure to complete the README.md file, add and push it.