CS45 Lab 1: Unix Shell Redux
Checkpoint: due Monday Jan 27, demo'ed during lab
This lab will be done with your assigned lab partner: Lab 1 partners
For the checkpoint: you should have a running shell program that can execute simple commands run in the foreground and background and that implements the built-in commands cd and exit. You also should have support for parsing at least one of: (1) commands with I/O re-direction (handling at least parsing one of the three, but all three would be better) or (2) commands with a pipe. You will demo your checkpoint to me during lab week 2. Prior to your demo create a test suite of a few simple commands that you can use to demo your shell's meeting the checkpoint requirements (you can just cut and past commands from your test suite during your demo). You only get 3 minutes for your demo, so plan it out and practice it before lab. I also encourage you to get farther than this by the checkpoint due date, but I only want to see the required checkpoint functionality during your short demo.
Content:
- Problem Introduction
- Getting Started
- Implementation Details
- Useful Unix System Calls
- What to Hand in
Required Features:
Your shell will supports the following required features:
- running simple commands in the foreground (e.g. ls -l -A)
- running a command in the background (using &)
- the built-in commands cd, and exit
- the built-in command history, and !! and !num
- commands with a single pipe
- commands with I/O re-direction
(using this re-direction syntax: 1>, 2>, <). - using the environment variable PATH to search for the command executable in the user's path
- using a signal handler on SIGCHLD to reap zombie children
Additional Requirements:
In addition to implementing the required shell functionality:
- your shell must be implemented in C (no C++)
- you must use the execv version of exec that passes the full path name to the executable file (you will use the PATH environment variable to find the full path and construct the full pathname string to pass to execv)
- you must use a makefile to build your shell program
- your shell should be robust to bad user input and gracefully handle errors (use perror where appropriate)
- your shell must be free of all memory access errors stemming from your code (run valgrind to verify this). Remember that every malloc needs a corresponding free.
- the parsing code should be implemented as a separate "library" (.c and .h) from the main shell code that uses it (in a different .c file).
- use a signal handler on SIGCHLD (your shell does not need to handle other signals)
- your code should use good modular design, be efficient, and well commented. See my C language links for information about good C programming style (commenting in particular), C language references and debugging tools.
- you may not use any global variables in your solution.
- you should not assume any max length to a command line (I suggest using the readline library to read in the command line)
First, one of you and your partner should set up a git repo for your lab 1 assignment and copy over the lab 1 starting point code. Follow these directions: setting up starting point for lab 1
After setting up your git repo and copying over my starting point files (which you are welcome to use or not), I suggest revisiting your CS31 shell solution and using it as a starting point or using parts of it as a guide for how to implement similar parts of this shell (be very careful about how this shell and the 31 shell differ). If you took 31 in Fall 2013, you can more easily use your CS31 shell program as a starting point for this one. If you took CS31 last year, use your shell program more as a guide for this one; start the design of this from scratch to match the specifications of this lab assignment, applying top-down design rather than trying to follow the structure of the CS31 shell program from last year and cramming in these new features. In either case you already have written shell main loop code for running commands in the foreground and background and some signal handling code that you may make use of in this shell.
Main Parts of this Lab:
There are two well defined pieces of code to write. The first is a set of command line parsing routines that take as input the command line entered by the user and parse it, and among other things create the argv string list for execv. The parsing routines must be able to identify and correctly parse command lines that include I/O redirection, running in the background, pipes, and built-in commands. The second is a set of functions for executing commands starting with a simple command, then incrementally adding and testing more features: built-in commands, commands with I/O redirection, commands with pipes.Even though there are two well defined pieces of functionality to write, dividing the work up into these two pieces is not suggested; these are not necessarily both the same amount of work, and it is important that you both know how to write shell code to execute a command with a pipe, for example, and that you both know how to parse a complicated command line and use environment variables to find executable files in the user's path. The most effective way to work on this lab is for you and your partner to work together in the lab on both pieces.
You and your partner should start by sketching out the design of your solution (use top-down design, use good modular design, and design function prototypes). Implement and test your code incrementally, and test individual functions in isolation as much as possible. For example, start with exec'ing a simple command with command path and argv strings for a specific command hard-coded into your shell program. Once this works, move on to adding the next piece of functionality, test and debug it, then move on to adding the next piece, and so on.
You may want to add assert statements during testing to test pre and post conditions of your functions (see the man page for assert), and make use of gdb and valgrind to help you find and fix bugs. Be sure that any printf's or assert statements you add for debugging purposes are removed from (or commented out of) the code you submit.
Shell Overview
(See the CS31 lab 7 assignment for more details on anything described in this section) A shell executes a loop:- print the shell prompt
- read the next command line (terminated with '\n')
- parse the command line (get each command name and its command line arguments, determine if it is a built-in, and if there is I/O redirection, running in the background, or a pipe in the command line)
- create the argv lists for execv if it is not a built-in
- execute the command(s) in the command line. For a built-in execute the command directly. For non-built-ins, fork one or more child processes to execute the command and for wait for it/them to finish (unless it is run in the background.)
- repeat, until the user enters the exit command
In general commands are in the form:
commandname arg1 arg2 arg3 ...To execute this command, the shell first checks if it is one of its built-ins, and if so invokes a functions to execute it. If it is not a built-in, the shell parses the command line and creates a child process(es) to execute the command.
Creating a new child process is done using the fork system call, and waiting for the child process to exit is done using the waitpid system call. fork creates a new process that shares its parent's address space (both the child and parent process continue at the instruction immediately following the call to fork. In the child process, fork returns 0, in the parent process, fork returns the pid of the child. The child process will call execv to execute the command. For example:
int child_pid = fork();
if(child_pid == -1) {
// fork failed...handle this error
} else if(child_pid == 0) {
// child process will execute code here to exec the command
...
execv(command_path, command_argv_list);
} else {
// parent process will execute this code
...
}
The execv system call overlays the calling process's image
with a new process image and begins execution at the starting point
in the new process image (e.g. the main function in a C program). As
a result, exec does not return unless there is an error (do you
understand why this is the case?).
The parent can call waitpid to block until a child exits:
pid = waitpid(childpid, &status, 0);or the parent can call waitpid in a signal handler on SIGCHLD to reap zombie children run in the background.
Parsing the command line and finding the command path name
Reading and Parsing the Command line
You are welcome to use any valid C method for reading in and parsing the command entered by the user. However, it is important that your method is robust to bad user input such as entering an empty command (your shell should just print the prompt again) or entering a badly formed command (your shell should print out an error message).Your parsing code should be implemented as a separate library (in .h and .c files) that is used by the main shell program. See the CS31 lab 8 assignment for some information on how to structure this (your parsing functions for this lab will be different then these).
Part of the parsing process involves creating the arguments to execv:
execv(command_path, command_argv_list);
The first argument is a string containing the path name to the command,
the second is a list of strings, one for each command line argument, the
list terminated by NULL.
For example, the arguments to execute the command ls -l would look
like this: execv("/bin/ls", arg_list); , where arg_list is:
arg[0]: "/bin/ls" arg[1]: "-l" arg[2]: NULL
See the "File I/O" and "strings" parts of my C help pages for some basic information about C strings and input functions. A couple functions that may be useful are readline and strtok. If you use readline, you need to link with the readline library:
gcc -g -o myshell myshell.c -lreadlineHere is some information about using the readline library. Also, look at the man pages for C library functions and system calls, and be careful about who is responsible for allocating and freeing memory space passed to (and returned by) these routines.
Finding the Path Name to entered commands
If the user enters a command using its path name, like any of the following examples:./a.out # a relative path name /bin/ls # an absolute path name ../foo # a relative path namethen the path name to the command (that is the first argument to execv) is part of the command line that you read in.
However, if the user enters a command using only its name:
ls foothen you need to search the user's path to find the command executable file and construct the a full path name string to pass to execv:
execv(full_path_to_command_executable, command_argv_list);
To do this, you will use user's PATH environment variable to try to
locate the executable file in the user's path, and once found
you will also test that the file is executable by the user before
constructing the full path name string to pass to execv.
Here are some details:
- Use the getenv system call to get the value of the
PATH environment variable:
path = getenv("PATH");path is an ordered list of directory paths in which to search for the command. It is in the form:"first_path:second_path:third_path: ..."For example, if the user's path is:/usr/swat/bin:/usr/local/bin:/usr/bin:/usr/sbin
the shell should first look for the cat executable file in /usr/swat/bin/cat. If it is not found there, then it should try /usr/local/bin/cat next, and so on.(FYI: you can list your PATH environment variable in bash by running echo $PATH, and all your environment variables by running the env command)
- access: check to see if a file is accessible in some way.
// check if is this file exists and is executable access(full_path_name_of_file, X_OK);
- Your shell needs to detect and handle the error of a non-existing command
Shell Built-ins
Before implementing a built-in function, first test out the command in bash to see what bash does: this will help you figure out functionality and correctness for your implementation.The only shell built-in functions you need to handle are cd, exit, and history (and !! and !num syntax for running commands from the history). Shell built-in functions are not executed by forking and exec'ing an executable, instead the shell process implements the command itself.
cd
To implement the cd command, your shell needs to change the value of the process' current working directory (cwd). Here are some examples:cd /usr/bin # should change cwd to /usr/bin cd # should change cwd to /home/you/ cd .. # should change cwd to the parent of current directoryAfter your shell executes a cd command, subsequent executions of pwd and ls by your shell should reflect the change in the cwd that is the result of executing the cd command.
Here are some functions you may find helpful in implementing cd (see their man pages for more details):
- getcwd: gets the absolute path name of the current working directory.
- chdir: change the value of cwd.
- getenv: can use to get the value of
the HOME environment variable
(try running echo $HOME in bash to see yours).
history, !!, and !num
myshell$ history # list the n most previous commands (10 in this example)
4 14:56 ls
5 14:56 cd texts/
6 14:57 ls
7 14:57 ls
8 14:57 cat hamlet.txt
9 14:57 cat hamlet.txt | grep off
10 14:57 pwd
11 14:57 whoami
12 14:57 ls
13 14:57 history
myshell$ !8 # executes command 8 from the history (cat hamlet.txt)
myshell$ !! # executes the last command again (cat hamlet.txt)
Implement history for a reasonable sized, but smallish, number of
previous commands (10-20 would be good, but design your program so
that you can easily change this size), and note that the command number
is always increasing.
Commands from the history list could be any type
(built-ins, run in the foreground, commands with pipe, ...), thus running
a command using !num or !! syntax can result in your shell
running any of these different types of commands.
Note that when !num !! are entered, the command line matching that command from the history is added as the most recent command line in the history list (e.g. the string "!9" would never show up in a listing when the user runs history). Try these out in bash to see how they work.
You may not use the readline library to implement history. Instead, implement a data structure for storing a command history, and use it when implementing the built-in history command and !num syntax to execute previous commands. Look at the CS31 shell lab for more information and hints on implementing the history command.
I/O Redirection and Pipes
I/O Redirection
Your shell needs to handle I/O re-direction using the 1>, 2>, and < syntax for specifying sdout, sderr, and stin re-direction. Here are some examples:cat foo 1> foo.out # re-direct cat's stdout to file foo.out cat foo 2> foo.err # re-direct cat's stderr to file foo.err cat foo 1> out1 2> out2 # re-direct cat's stdout to out1 and stderr to out2 cat foo < foo.in # re-direct cat's stdin from file foo.out cat foo < foo.in 1> foo.out # re-direct cat's stdin and stdoutI/O re-direction using '>' or '>&' need not be supported. For example, the following command can be an error in your shell even though it is a valid Unix command:
$ cat foo > foo.out2
Each process that is created (forked), gets a copy of its parent's file descriptor table. Every process has three default file identifiers in its file descriptor table, stdin (file descriptor 0), stout (file descriptor 1), and stderr (file descriptor 2). The default values for each are the keyboard for stdin, and the terminal display for stdout and stderr. A shell re-directs its child process's I/O by manipulating the child's file identifiers (think carefully about at which point in the fork-exec process this needs to be done). You will need to use the open, close and dup system calls to redirect I/O.
Pipes
A pipe is an interprocess communication (IPC) mechanism for two Unix process running on the same machine. A pipe is a one-way communication channel between the two processes (one process always writes to one end of the pipe, the other process always reads from the other end of the pipe). A pipe is like a temporary file with two open ends, writes to one end by one process can be read from the other end by the another process. However, unlike a regular file, a read from a pipe results in the removal of data that was written by the other process. The pipe system call is used to create a new pipe. It creates two file descriptors, one for the read end of the pipe, the other for the write end of the pipe. One of the communicating processes use the write end of the pipe to send a message to the other communication process who reads from the read end: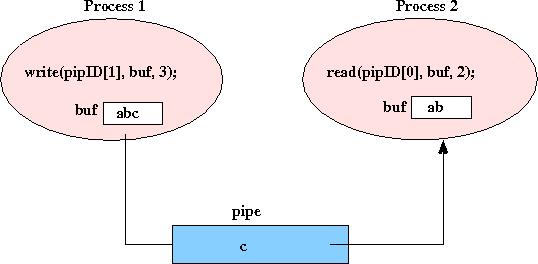
When your shell program executes a command with a single pipe like the following:
cat foo.txt | grep -i blahcat's output will be pipe'ed to grep's input. The shell process will fork two process (one that will exec cat the other that will exec grep), and will wait for both to finish before printing the next shell prompt. Use pipe and I/O redirection to set up communication between the two child processes.
The process reading from the pipe will automatically exit after it reads EOF
on its input; any process blocked on a read will unblock when the
write end is closed and "read" EOF. If multiple processes have
the same file open, only the last close
to the file will trigger this EOF behavior. Therefore, when you write
programs that create pipes (or open files), you need to be very
careful about how many processes have the files open, so that EOF
conditions will be triggered.
- chdir: change the current working directory (use this to implement cd)
- fork-join: create a new child process and wait
for it to exit:
int cpid = fork(); if (cpid == -1) { // fork failed, handle the error } else if (cpid == 0) { // the child process } else { // the parent process pid = waitpid(cpid, &status, 0); } - execv: overlay a new process image on calling process
execv( command_path, command_argv_list); - waitpid: to wait for a child process to terminate and/or to reap
a terminated child process.
pid_t waitpid(pid_t pid, int *status, int options); // examples: // wait for specific child process to exit (its pid is passed in pid param) pid = waitpid(pid, &status, 0); // reap any child process that has exited (-1) // but don't wait if none have exited (WNOHANG): pid = waitpid(-1, &status, WNOHANG);
- signal: to register a signal handler function on a particular signal:
sighandler_t signal(int signum, sighandler_t handler); // example: signal(SIGCHLD, my_sig_child_hdlr); // signal handler functions must have a prototype matching this: // void my_sig_child_hdlr(int sig);
- open, close, dup: for I/O re-direction
For example to re-direct stdout to file foo:
int fid = open("foo", O_WRONLY | O_CREAT, 0666); // open file foo close(1); // close stdout's file descriptor (slot 1 in open file table) dup(fid); // dup file descriptor fid, the duplicate open entry will go // into the first free slot in the open file table (slot 1) close(fid); // we don't need fid open any moreNow when the process writes to stdout (to file descriptor 1), the output will go to the file foo instead of to the terminal. - pipe: IPC mechanism for iter-machine processes
int pipe_id[2]; pipe(pipe_id); read(pipe[0], in_buf, len); write(pipe[1], out_buf, len); - assert: useful for testing pre and post conditions during
debugging (see the man page for more information):
assert(x == 9);
- perror: useful for printing out error-specific messages when calls
to system calls return an error value:
pid = fork(); if(pid < 0) { // error perror("fork failed\n"); // prints this AND an error specific message ... } - fflush: forces output to be written to terminal
printf("hello\n"); fflush(stdout); // force all buffered output to be printed to stdout now - kill and pkill:
Your correct shell program should reap all exited children and not leave
around zombie children. However, in its development stages, you may find
that it creates zombie processes that it never reaps. You should check
for, and kill, all zombies after running your shell program.
To do this, after running your shell program, run ps in bash to see
if you have left any un-reaped zombie children (or any extra instances
of your shell program still running):
ps 233 pts/7 00:00:01 sleeper <zombie>
If so, send it (them) a kill signal to die using either kill -9 or pkill -9:kill -9 233 # kills the process with pid 233 pkill -9 sleeper # kills all sleeper process
- Testing your shell and creating a test suite:
In testing your shell, if you are ever unsure about the output of a command line, try running the same command line in bash and see what it does.I also encourage you to create a test suite of command files that you use to test different aspects of your shell. You can run you shell interactively entering a command at a time, but you can also use I/O re-direction to test a set of command from a file quickly. If, for example, I have the following commands in a file named testfile:
ls ls -l -a /bin/ls -l -a exit
I can run my shell on these doing:./myshell < testfile
A test suite is good for correctness testing as you make changes to your code: have a list of commands that your shell can handle in a file(s), and run your shell on these files to make sure that your the change didn't break something that was working.Here are some examples of commands that your shell should handle (this is not a complete test suite; you should come up with a much more complete test suite for your shell): example shell commands
- My help pages contain information about C programming, Unix utilities, and some system calls that you may find helpful.
You will submit a single tar file containing your lab 1 solution code and the other specific contents listed below, using cs45handin Only one of you or your partner should submit your tar file via cs45handin. If you accidentally both submit it, send me email right away letting me know which of the two solutions I should keep and which I should discard. You can run cs45handin as many times as you like, and only the most recent submission will be recorded.
Your lab1 tar file should include the following (see Unix Tools for more information on script, dos2unix, make, and tar):
- A README file with:
- Your name and your partner's name
- If you have not fully implemented all shell functionality then list the parts that work (and how to test them if it is not obvious) so that you can be sure to receive credit for the parts you do have working.
- Tell me how to find comments in your sample output file (ex. They are prefixed by the character string "###")
- All the source files needed to compile, run and test your code
(Makefile, .c files, .h files, and optional test scripts). Please do not
submit object (.o) or executable files (I can build these using your Makefile).
- A file containing the output from your testing of your shell program.
Make sure to demonstrate:
- simple Unix commands
- built-in commands
- I/O redirection
- pipes
- error conditions
script(script takes an optional filename arg. Without it, script's output will go to a file named typescript)$ script Script started, file is typescript % ./myshell myshell$ ls foo.txt myshell myshell$ exit good bye % exit exit Script done, file is typescript
Then clean-up the typescript file by runningdos2unix$ dos2unix -f typescript # you may need to run dos2unix more than once to remove all control chars $ mv typescript outputfile
Finally, edit the output file by inserting comments around the specific parts that you tested that are easy for me to find and that explain what you are testing. The idea is for you to ensure that if you shell correctly implements some feature, that I can test it for that feature. By showing me an example of how you tested it for a feature and making sure that I can easily find your test it will make it more likely that I am able to verify that a feature works in your shell program. For example, you could put special characters before your comments so that they are easy for me to find (like using '#' in the following example):# # Here I am showing how my shell handles the built-in commands # myshell$ cd ... # # Here I am showing how my shell handles commands with pipes # myshell$ cat foo.txt | grep blah ...