This, and all, lab assignments should be done with a partner. See the Wed lab page for information about how you can set up a git repository for your joint lab 1 project.
| Lab 1 Partners | ||
| Peter Ballen and Greg Rawson | Katherine Bertaut and Greg Taschuk | Sam Clark and Elliot Padgett |
| Chritina Duron and Kevin Li | Nick Felt and Nick Rhinehart | Jonathan Gluck and Kevin Pytlar |
| Phil Koonce and Steven Hwang | Jacob Lewin and Luis Ramirez | Ben Lipton and Allen Welkie |
| Niels Verosky and Steve Dini | Catie Meador and Becca Roelofs | Andrew Stromme and Sam White |
See my C language links for information about C programming style, debugging tools, etc.
Even though there are two well defined pieces of functionality to write, dividing the work up into these two pieces is not suggested; these are not necessarily both the same amount of work, and it is important that you both know how to write shell code to execute a command with a pipe, for example, and that you both know how to parse a command line. I think the most effective way to work on this lab is for you and your partner to work together in the lab on both pieces. You may go off and do some parts independently, but come back together often to work on figuring out portions of the task, and to do incremental testing and debugging (two pairs of eyes are better than one.)
You and your partner should start by sketching out the design of your solution (use top-down design, use good modular design, and design function prototypes). Implement and test your code incrementally, and test individual functions in isolation as much as possible. For example, start with exec'ing a simple command with command path and argv strings for a specific command hard-coded into your shell program. Once this works, move on to adding the next piece of functionality, test and debug it, then move on to adding the next piece, and so on.
You may want to add assert statements during testing to test pre and post conditions of your functions (see the man page for assert), and make use of gdb and valgrind to help you find and fix bugs. Be sure that any printf's or assert statements you add for debugging purposes are removed from (or commented out of) the code you submit.
You could use the .c, .h and Makefile from Wednesday's lab as a
starting point for your shell program:
~newhall/public/cs45/lab1
myshell$ ls -la # long listing of curr directory -rw------- 1 newhall users 628 Aug 14 11:25 Makefile -rw------- 1 newhall users 34 Aug 14 11:21 foo.txt -rw------- 1 newhall users 16499 Aug 14 11:26 main.c myshell$ cat foo 1> foo.out # cat foo's contents to file foo.out myshell$ pwd # print current working directory /home/newhall/public myshell$ cd # cd to HOME directory myshell$ pwd /home/newhall myshell$ firefox & # run firefox in the background myshell$cd is a built-in commands, and pwd, ls, and cat are commands executed by a child forked by the shell process.
In general commands are in the form:
commandname arg1 arg2 arg3 ...To execute this command, the shell first checks if it is one of its built-ins, and if so invokes a functions to execute it. If it is not a built-in, the shell parses the command line creates a child process to execute the command, and waits for the child to complete the execution of the command.
Creating a new child process is done using the fork system call, and waiting for the child process to exit is done using the wait system call. fork creates a new process that shares its parent's address space (both the child and parent process continue at the instruction immediately following the call to fork. In the child process, fork returns 0, in the parent process, fork returns the pid of the child. The child process will call execvp to execute the command. For example:
int child_pid = fork();
if(child_pid == -1) {
// fork failed...handle this error
} else if(child_pid == 0) {
// child process will execute code here to exec the command
...
execvp(command_name, command_argv_list);
} else {
// parent process will execute this code
...
}
The parent can call wait or waitpid to block until a child exits:
// block until one of my child processes exits (any one): pid = wait(&status); // block until child process exits // OR to wait for a specific child process to exit: pid = waitpid(childpid, &status, 0);The execvp system call overlays the calling process's image with a new process image and begins execution at the starting point in the new process image (e.g. the main function in a C program). As a result, exec does not return unless there is an error (do you understand why this is the case?).
Part of the parsing process involves creating the arguments to exec:
execvp(command_name, command_argv_list);
The first argument is a string containing the command name, the second
is a list of strings. The first string int the list is the command name,
followed by one string per command line argument, followed by the NULL string.
For example, the arguments to execute the command ls -l would look
like this: execvp("ls", arg_list); , where arg_list is:
arg[0]: "ls" arg[1]: "-l" arg[2]: NULL
See the "File I/O" and "strings" parts of my C help pages for some basic information about C strings and input functions. A couple functions that may be useful are readline and strtok. If you use readline, you need to link with the readline library:
gcc -g -o myshell myshell.c -lreadlineHere is some information about using the readline library. Also, look at the man pages for C library functions and system calls, and be careful about who is responsible for allocating and freeing memory space passed to (and returned by) these routines.
cd,
and exit. For more information on shell
built-in functions look at the builtins man page. Shell built-in
functions are not executed by forking and exec'ing an executable. Instead,
the shell process performs the command itself.
To implement the cd command, your shell should get the value of its current working directory (cwd) by calling getcwd on start-up. When the user enters the cd command, you must change the current working directory by calling chdir(). Subsequent calls to pwd or ls should reflect the change in the cwd as a result of executing cd.
foo 1> foo.out # re-direct foo's stdout to file foo.out foo 2> foo.err # re-direct foo's stderr to file foo.err foo 1> foo.out2 2> foo.out2 # re-direct foo's stdout & stderr to foo.out2 foo < foo.in # re-direct foo's stdin from file foo.out foo < foo.in 1> foo.out # re-direct foo's stdin and stdoutI/O re-direction using '>' or '>&' need not be supported. For example, the following command can be an error in your shell even though it is a valid Unix command:
$ cat foo > foo.out2
Each process that is created (forked), gets a copy of its parent's file descriptor table. Every process has three default file identifiers in its file descriptor table, stdin (file descriptor 0), stout (file descriptor 1), and stderr (file descriptor 2). The default values for each are the keyboard for stdin, and the terminal display for stdout and stderr. A shell re-directs its child process's I/O by manipulating the child's file identifiers (think carefully about at which point in the fork-exec process this needs to be done). You will need to use the open, close and dup system calls to redirect I/O.
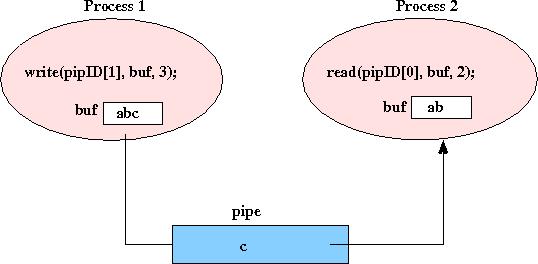
When your shell program executes a command with a single pipe like the following:
cat foo.txt | grep -i blahcat's output will be pipe'ed to grep's input. The shell process will fork two process (one that will exec cat the other that will exec grep), and will wait for both to finish before printing the next shell prompt. Use pipe and I/O redirection to set up communication between the two child processes.
The pipe reading process knows when to exit when it reads EOF on its input;
any process blocked on a read will unblock when the file is closed.
However, if multiple processes have the same file open, only the last close
to the file will trigger an EOF. Therefore, when you write programs that
create pipes (or open files), you need to be very
careful about how many processes have the files open, so that EOF
conditions will be triggered.
Here are some examples of commands that your shell should handle
(this is not a complete test suite; you should come up with
a much more complete test suite for your shell):
Here are some additional features to try adding if you have time
(some are much more difficult than others):
To see your path: echo $PATH. To list
the value of all your environment variables: env.
Useful Unix System Calls
Here are some Unix system calls that you may find useful, and some
examples of how to use them (note: the examples
may not match exactly how you need to use them in your shell program):
int cpid = fork();
if (cpid == -1) { // fork failed, handle the error
} else if (cpid == 0) { // the child process
} else { // the parent process
pid = waitpid(cpid, &status, 0);
}
execvp( command_name, command_argv_list);
int fid = open("foo", O_WRONLY | O_CREAT, 0666); // open file foo
close(1); // close stdout's file descriptor (slot 1 in open file table)
dup(fid); // dup file descriptor fid, the duplicate open entry will go
// into the first free slot in the open file table (slot 1)
close(fid); // we don't need fid open any more
Now when the process writes to stdout (to file descriptor 1), the
output will go to the file foo instead of to the terminal.
int pipe_id[2];
pipe(pipe_id);
read(pipe[0], in_buf, len);
write(pipe[1], out_buf, len);
Test Commands
In testing your shell, if you are ever unsure about the output of a
command line, try running the same command line in bash and
see what it does.
myshell$
myshell$ ls
myshell$ ls -al
myshell$ cat foo.txt
myshell$ cd /usr/bin
myshell$ ls
myshell$ cd ../
myshell$ pwd
myshell$ cd
myshell$ find . -name foo.txt
myshell$ wc foo.txt
myshell$ wc blah.txt
myshell$ /usr/bin/ps
myshell$ ps
myshell$ firefox
myshell$ exit
myshell$ cat foo.txt | more
myshell$ cat foo.txt | grep blah
myshell$ cat foo.txt blah.txt 1> out.txt 2> out.txt
myshell$ wc out.txt
myshell$ cat < foo.txt 1> out2.txt
myshell$ diff out.txt out2.txt
myshell$ ls -la yeeha.txt 2> errorout.txt
myshell$ exit
## test some error conditions
## your shell should gracefully handle
## errors by printing a useful error message and not crash or exit (it
## should just restart its main loop: print shell prompt, ...)
myshell$ |
myshell$ ls 1 > out
myshell$ cat foo1> out
myshell$ 1> < 2>
Extra Credit
Try these mostly for fun and for a few extra credit points.
However, do not try these until your basic shell program is complete, correct,
robust, and bug free; an incomplete program with extra credit features
will be worth much less than a complete program with no extra credit features.
execv(full_path_to_command_executable, command_argv_list);
execv's first argument is the full path name to the command's
executable file. This change requires that your shell
searches for the executable file using the user's PATH
environment variable, and that it tests permissions on the executable
file to ensure that it is executable by this user.
Some details:
% cat foo.txt
the shell program needs to locate the cat executable file in the user's
path.
path = getenv("PATH");
path is an ordered list of directory paths in which to
search for the command. It is in the form:
"first_path:second_path:third_path: ..."
For example, if the user's path is:
/usr/swat/bin:/usr/local/bin:/usr/bin:/usr/sbin
the shell should first look for the cat executable file in
/usr/swat/bin/cat. If it is not found there,
then it should try /usr/local/bin/cat next, and so on.
// check if is this file exists and is executable
access(full_path_name_of_file, X_OK);
myshell< history # list the n most previous commands (10 in this example)
4 14:56 ls
5 14:56 cd texts/
6 14:57 ls
7 14:57 ls
8 14:57 cat hamlet.txt
9 14:57 cat hamlet.txt | grep off
10 14:57 pwd
11 14:57 whoami
12 14:57 ls
13 14:57 history
myshell< !8 # will execute command 8 from the history
Implement history for a reasonable sized, but smallish, number of
previous commands (50 would be good). And note that the command number
is always increasing. Don't use the readline functionality to do this.
Instead, implement a data structure for storing a command history, and
use it when implementing the built-in history command and !num syntax
to execute previous commands.
gcc -g -o myshell myshell.c -lncurses -lreadline
myshell$ cat foo | grep blah | grep grrr | grep yee_ha
What to Hand in
Submit a single tar file with the following contents using
cs45handin
(see
Unix Tools for more information on script, dos2unix, make, and tar):
script
(script takes an optional filename arg. Without it, script's output will
go to a file named typescript)
$ script Script started, file is typescript % ./myshell myshell$ ls foo.txt myshell myshell$ exit good bye % exit exit Script done, file is typescriptThen clean-up the typescript file by running
dos2unix
$ dos2unix typescript # you may need to run dos2unix more than once to remove all control chars $ mv typescript outputfileFinally, edit the output file by inserting comments around the specific parts that you tested that are easy for me to find and that explain what you are testing. The idea is for you to ensure that if you shell correctly implements some feature, that I can test it for that feature. By showing me an example of how you tested it for a feature and making sure that I can easily find your test it will make it more likely that I am able to verify that a feature works in your shell program. For example, you could put special characters before your comments so that they are easy for me to find (like using '#' in the following example):
# # Here I am showing how my shell handles the built-in commands # myshell$ cd ... # # Here I am showing how my shell handles commands with pipes # myshell$ cat foo.txt | grep blah ...