CS44 Lab 6: Movie Database
Quick Links
- Introduction
- Creating the DB
- Queries
- Requirements
- Tips and Additional Details
- Example Ouput
- Submitting your lab
This assignment is to be done with your Lab Partner. You may not work with other groups, and the share of workload must be even between both partners. Failing to do either is a violation of the department Academic Integrity policy. Please read over Expectations for Working with Partners on CS Lab work.
In this lab, you will create a relational movie database and pose a set
of queries using SQLite.
The raw data has been extracted from the
Internet Movie Database (IMDb).
You will structure this data in 6 tables to represent Movies,
Actors, Directors, Genres, the relationship between director(s) for
each movie (DirectsMovie), and the casts of each movie (Casts).
Your schema is closely related to the following ER diagram:
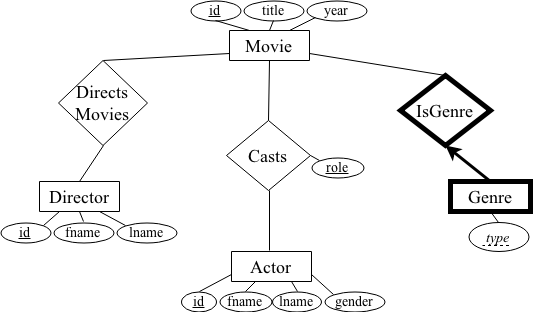
In addition, you will use embedded SQL to write a Python program to interface with the sqlite3 engine. While there is a bit of a learning curve to picking up the Python library for sqlite3, the SQL commands are equivalent to those you would enter on the normal command-line interface.
Lab Goals:
- to gain experience with one popular instance of a relational database (SQLite)
- to combine procedural language (Python) elements with declarative language (SQL) constructs
- to practice data definition language (DDL) commands in SQL
- to design queries to answer questions about the data
- to utilize indices and query planning to make your queries efficient
Next, clone your Lab 6 git repo into your cs44/labs subdirectory:
cd cd cs44/labs git clone [the ssh url to your repo] cd Lab6-partner1-partner2
If this didn't work, or for more detailed instructions on git see: the Using Git page (follow the instructions for repos on Swarthmore's GitHub Enterprise server).
Your Lab6 repo contains the following files (those that require modification are in blue):- createDB.py - a main program for creating your initial database schema including the creation of tables and indices plus the insertion of records. You will only need to run this program one time once you get it working (but be sure to test it!)
- queryDB.py - the main user program. This program will prompt the user with a menu of all possible queries to run and execute the user's choice(s)
- /home/newhall/public/cs44/movieDB/ - this folder contains the records to insert into your tables in the form of relationName.txt (e.g., Casts.txt contains all records of actors cast in a movie)
- README - the usual data collection
Next, you should read a few references on using the sqlite library in Python:
- SQLite API - a detailed description of the full library interface. This is a good reference for help on accomplishing specific tasks or inspecting data
- Python tutorial - a quick-start guide for the basics of opening a database connection
- Python Central tutorial guide - another quick-start guide
- When in doubt, google the specific topic. Start your search with "sqlite python"; e.g., how do I retrieve query results? Google: sqlite python retrieve query results.
In createDB.py, you will place your code to create the movie database.
You will create tables, insert values into the table, and create indices
on the table as needed to solve your queries efficiently. The code has
been partially provided to help you get started.
NOTE: do not use your home directory to create the actual database -
this will eat up your quota very quickly.
See this page for tips on where to store your data:
Tips for Performance and Storage.
Schema
The schema is as follows:
Actor (id, fname, lname, gender)
Movie (id, title, year)
Director (id, fname, lname)
Casts (actorID, movieID, role)
DirectsMovie (directorID, movieID)
Genre (movieID, type)
All id fields are integers, as is year. All other fields are character strings. You can use either CHAR(N) or VARCHAR(N) for the character strings. Generally, stick to a maximum of 30 characters for any name or title field; 50 for role and type; 1 character for gender.
The keys are specified in italics above. To sum up: id is the key for Actor, Movie, and Director. For the remaining relations, the primary key is the combination of all attributes. This is because an actor can appear in a movie many times in different roles; each movie can fit multiple genres; and each movie can have multiple directors.
The foreign keys should be clear from the context. Casts.actorID references Actor.id. Casts.movieID and DirectsMovie.movieID reference Movie.id. DirectsMovie.directorID references Directors.id The IMDb dataset is not perfectly clean and some entries in Genre.movieID refer to non-existing movies. This is the reality of "messy" data in the real world. In this instance, we drop the constraint rather than cleaning up the data. DO NOT specify that Genre.movieID is a foreign key.
Required methods
You will define the following functions:- main()
Takes the file name for the new data base as a command-line argument. This function should be minimal and delegate work to the helper methods. It should check if the file already exists, establish a connection, create all tables, insert all values, and finish up by building indices. - checkDB(filename)
Determines if the file already exists (HINT: use the os.path library). If not, you may return to the main program proceed to construct the database. If it does already exist, the user should be prompted with the option of deleting the file (os.remove()) or quitting. If they chose to delete, remove the file and proceed with creating the database. - createTables()
Issues SQL commands to create all 6 tables in the schema. Be sure to turn foreign keys ON first. - insertValues()
You may not use .import to import all values. Instead, you must read each file, parsing the arguments on each line, and insert the results one-by-one using the INSERT INTO SQL command. You may want to take a look at executemany() function to see how all insertions can be executed at one time. - createIndex()
Place all SQL commands for creating indices here. You should choose your indices wisely. You will probably need to complete this function after solving some of the queries below. As an aside, most queries should run quickly (less than a few second). In the README file, you should provide a justification for each index constructed by citing which queries it is useful for.
In queryDB.py, you will define your queries and implement a user interface for interacting with the database. Your main method should establish a connection in a similar fashion as createDB.py: read the name of the database from the command line, check to see if the file exists (exit cleanly if it does not), establish a connection and cursor. See the example run output below.
Next, your program should repeatedly print a menu of options until the user selects "Exit" as an option. The menu has been provided for you in printMenu. Please do not change this method. After the user enters a choice, you should call the appropriate query.
Requirements
Be sure to follow these requirements:- Each query should be defined in a function queryX where X is the number below. For example the first query listed in the Queries table below should be defined in query1().
- Your queries should be easy to read.
Your SQL commands are sent as strings through the execute
method. Since these queries can be long, entering them as a very long
line string will make them very hard to read. Instead,
you should use Python's multi-string format
(i.e., """Long string""" to insert line breaks and make
the queries easy to read. For example, to
query the number of Directors named "Steven":
command = """ SELECT COUNT(*) FROM Directors D WHERE D.name = 'Steven' """ db.execute(command) results = db.fetchall() - Print out the query plan before each query. To get
the query plan prefix
EXPLAIN QUERY PLAN to
the query:
db.execute( "EXPLAIN QUERY PLAN\n" + command ) results = db.fetchall() # results contains the query plan not the query result
- Your SQL queries should be written so that they are run
relatively efficiently. sqlite will make use of indexes if they
exist. Try out queries in sqlite command line, look at the query plan,
and think about re-structuring and adding indexes to improve the performance
of slow queries (see Tips below).
- You should print out the time it takes to perform each query. To
time around some code in python:
start = time.time() # code you want to time end = time.time() print "\nCompleted in %.3f seconds" % (end-start)
- You are allowed to create temporary tables to store intermediate
queries. But you must drop temporary tables as soon as you complete
the query. For example, if my query creates a temporary
restult in a table named MyTable:
db.execute("DROP TABLE MyTable") - You should format your results in an easy to read manner. It is advised you write a function for printing results that you can call after each query. You should first print out the column headers (take a look at the Cursor's description field which has a set of tuples with the column name as the first element in each tuple). Then print out each returned tuple.
Queries
You will need to answer the following queries. Since there are many ways to write the same query, I ask that you sort your final results as specified to make comparisons easier. Additional attributes are attributes that should appear in your results but are not relevant to the sort ordering.| Query # | Description | Sort order | Additional attributes |
|---|---|---|---|
| 1 | List the names of all actors in the movie "The Princess Bride" | Actor's first name, Actor's last name | |
| 2 | Ask the user for the name of an actor, and print all the movies starring an actor with that name (only print each title once). | Movie title | |
| 3 | Ask the user for the name of two actors. Print the names of all movies in which those two actors co-starred (i.e., the movie starred both actors). | Movie id | Movie title |
| 4 | List all directors who directed 500 movies or more, in descending order of the number of movies they directed. Return the directors' names and the number of movies each of them directed. | Number of movies directed | Director's first name and last name |
| 5 | Find Kevin Bacon's favorite co-stars. Print all actors as well as the number of movies that actor has co-starred with Kevin Bacon (but only if they've acted together in 8 movies or more). Be sure that Kevin Bacon isn't in your results! | Number of movies co-starred | Co-stars first name and last name |
| 6 | Find actors who played five or more roles in the same movie during the year 2010. | Number of roles, Movie title | Actor's first name and last name |
| 7 | Programmer's Choice: develop your own query. It should be both meaningful and non-trivial - show off your relational reasoning skills! (But keep the query under a minute of run time) | ||
It is up to you to evaluate your query results for correctness and efficiency. However, Partial Sample Output shows partial output for some of the queries to help you understand what your program should do. The output includes an estimate (it should be close to this number) for the number of tuples queries will return, and the time it takes for my queries to run (see if you can beat my time).
- Implement createDB.py to create the database (your .db file in /local) from the raw data files. It contains the definition of schema and indices, and it loads the raw data into each relation. See details about the required methods listed above.
- Implement queryDB.py. This is a main user program that loads your your database (.db), enters a loop asking user to select a query, and the performs the selected query, outputing the results. See detailed requirements listed above.
- Create a file named queryoutput.txt that is all the output from a
run of your queryDB.py showing the results of your seven queries.
Use
script to capture
terminal output to a file. Use dos2unix to clean up the file and also
clean up any other stuff from the file by hand.
script queryoutput.txt .... exit dos2unix -f output.txt
- README.md: answer questions about the design of your database in this file.
- See this page for tips on where to store your data: Tips for Performance and Storage.
- You will want to divorce SQL errors from Python errors as much as
possible. Since SQL queries are roughly the same in both sqlite and the
Python interface to sqlite, you should practice running your queries
using the sqlite command-line interface. Note that a DB created using
Python can be inspected by loading it up in sqlite. For example:
# see Tips for Performance and Storage about using /local # once successfully created, you do not need to run this every time $ python createDB.py /local/tnas/movie.db $ sqlite3 /local/me_n_pal/movie.db SQLite version 3.7.9 2011-11-01 00:52:41 Enter ".help" for instructions Enter SQL statements terminated with a ";" sqlite> .table .table Actor Casts DirectMovie Director Genre Movie sqlite>
- This data set is pretty large. createDB.py may take awhile to insert all of the values and construct the indices (~10 minutes). Your queries, however, should all run fairly quickly.
- Coming up with a generic print function for your query results can seem
difficult. The description attribute of your Cursor
object (i.e., db.description) can be helpful. In particular,
the length of description is equal to the number of columns in the
result. The first item in each row of description is the column
name. So, to print out the ith column name using 20 spaces:
print "%-20s" % db.description[i][0]
To print each tuple, you can also allocate 20 spaces for each attribute value. In fact, you can create a format string pretty easily:formString = "%-20s " * len(db.description)
Then, fill in the templates using a tuple. For example, if you store a result into a tuple called result, you can print it out simply:print formString % result
- Creating the database can take a long time. Be sure to practice your commands in the SQLite environment first. Also, if you need to add to add an index after the fact, feel free to do this manually without having to reconstruct the db from scratch. Just be sure to test this works in your original code as well before handing in.
- Query taking a long time? Try breaking up the query into multiple pieces, saving intermediate results using the CREATE TABLE name AS ... syntax. Sqlite may not optimize nested queries well in certain cases, so if the nest is a static table, it may be faster to pre-calculate the table.
- In some cases, you might get a query closer to a minute depending on how you write the query. If your query is under a minute, you are probably fine. There is a fast (less than a second) solution for most of the queries and all queries can run in less than 30 seconds. You are not required to fully optimize all queries, but you should avoid very poor performance on any individual query.
From your local repo (in your ~you/cs44/labs/Lab06-partner1-partner2 subdirectory)
git add *.py git add README.md git add queryoutput.txt git commit -m "our complete, correct, robust, and well commented solution for grading" git push
If that doesn't work, take a look at the "Troubleshooting" section of the Using git page. Also, be sure to complete the questions in the README.md file, add commit, and push it.