CS44 Lab 1: Building a Buffer Manager
This assignment is to be done with your assigned Lab 1 partner. You may not work with other groups, and the share of workload must be even between both partners. Failing to do either is a violation of the department Academic Integrity policy. Please read over Expectations for Working with Partners on CS Lab work
Lab 1 Partner List for Lab Section A
Lab 1 Partner List for Lab Section B
Lab 1 Goals
The goal of the WiscDB projects is to allow students to learn about the internals of a data processing engine. In this first assignment, you will build a buffer manager, on top of an I/O Layer that I provide. Future labs will add additional layers to the DB code.The code base is quite extensive and will require much reading of API documentation and thorough testing. You are responsible for making significant progress early on; waiting until the last few days will not be manageable. The goals of this assignment include:
- Understanding the duties of the Buffer Management layer of a database
- Simulating the management of main memory and an appropriate replacement policy
- Navigating provided documentation to utilize a provided interface for the disk I/O layer.
- Developing a testing strategy for a large, intricate system.
- Using a formal commenting/documentation techniques (Doxygen) to create a clear, understandable code base.
Next, clone your Lab 1 git repo into your cs44/labs subdirectory, cd into your repo, and run make setup to build symlinks to library code needed to build the executable:
cd cd cs44/labs git clone [the ssh url to your repo] cd Lab1-partner1-partner2 make setupHere are some instructions on Using Git page (follow the instructions for repos on Swarthmore's GitHub Enterprise server).
If all was successful, you should see the following files and symlinks (files highlighted in blue require modification):
Lab 1 starting point files include
- Makefile - pre-defined. You may edit this file to add extra source files or execution commands.
- include/ - symlink to directory that contains header files for the Page, File and related classes. These cannot be modified, but you can open the header files in vim to see their contents. Each class must be well understood to manage the interface to the I/O layer. While reading the header files may be helpful, you should start with the online WiscDB documents first.
- lib/ - symlink to necessary object files. The contents of this directory can be ignored.
- exceptions/ - symlink to directory containing definitions of the list of possible exceptions for WiscDB. You will need to reference these exceptions to both handle possible errors that can be thrown to you or that you must throw. Again, you can open the .h files and read them, but it is probably easier to refer to the online documentation.
- buffer.h/.cpp - You must edit these files to implement the BufferManager and related Frame class. The header file has been completed for you, including the BufferStats class.
- bufferHashTable.h/.cpp - Defines the BufferHashTable class which maps pages to frames in the buffer pool for quick reference. You must complete the implementation for the provided definition.
- main.cpp - The provided code demonstrates usage of the Page and File classes. In addition, there are several very basic tests for the buffer manager. You must comment these tests and augment them to thoroughly test your buffer manager.
- README.md - a few wrap-up questions for you to answer about the lab assignment.
The lowest layer of the WiscDB database systems is the I/O layer. This layer allows the upper level of the system to:
- create/destroy files
- allocate/deallocate pages within a file
- insert/retrieve/update records within a page
- read and write pages of a file
Before reading further you should first read the documentation that describes the I/O layer of WiscDB so that you understand its capabilities. In a nutshell the I/O layer provides an object-oriented interface to the Unix file system with methods to open and close files and to read/write pages of a file. You will utilize these methods to move pages into the buffer pool and higher-level methods (e.g., main.cpp to process a query.
A database buffer pool is an array of fixed-sized memory buffers called frames that are used to hold database pages (also called blocks) that have been read from disk into memory. A page is the unit of transfer between the disk and the buffer pool residing in main memory. Most modern database systems use a page size of at least 8,192 bytes. Another important thing to note is that a database page in memory is an exact copy of the corresponding page on disk when it is first read in. Once a page has been read from disk to the buffer pool, the DBMS software can update information stored on the page, causing the copy in the buffer pool to be different from the copy on disk. Such pages are termed "dirty".
Since the database on disk itself is often larger than the amount of main memory that is available for the buffer pool, only a subset of the database pages fit in memory at any given time. The buffer manager is used to control which pages are memory resident. Whenever the buffer manager receives a request for a data page, the buffer manager checks to see if the requested page is already in the one of the frames that constitutes the buffer pool. If so, the buffer manager simply returns a pointer to the page. If not, the buffer manager frees a frame (possibly by writing the page to disk if it is dirty) and then loads the requested page from disk into the newly available frame.
Replacement Policy and the Clock Algorithm
 There are many ways of deciding which page to replace when a free frame is
needed. Commonly used policies in operating systems are FIFO (first in first
out), MRU (most recently used), and LRU (least recently used).
LRU, arguably the most useful policy, suffers from high overhead costs
due to the need for a priority queue. An alternative approach,
the circular array buffer, or clock algorithm,
approximates LRU behavior with much better run time performance.
There are many ways of deciding which page to replace when a free frame is
needed. Commonly used policies in operating systems are FIFO (first in first
out), MRU (most recently used), and LRU (least recently used).
LRU, arguably the most useful policy, suffers from high overhead costs
due to the need for a priority queue. An alternative approach,
the circular array buffer, or clock algorithm,
approximates LRU behavior with much better run time performance.
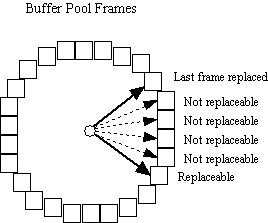
The image to the left shows the conceptual idea of the clock array. Each square box corresponds to a frame in the buffer pool. Assume that the buffer pool contains numFrames frames, numbered 0 to numFrames-1. Conceptually, all the frames in the buffer pool are arranged in a circular list. Associated with each frame is a bit termed the refbit.
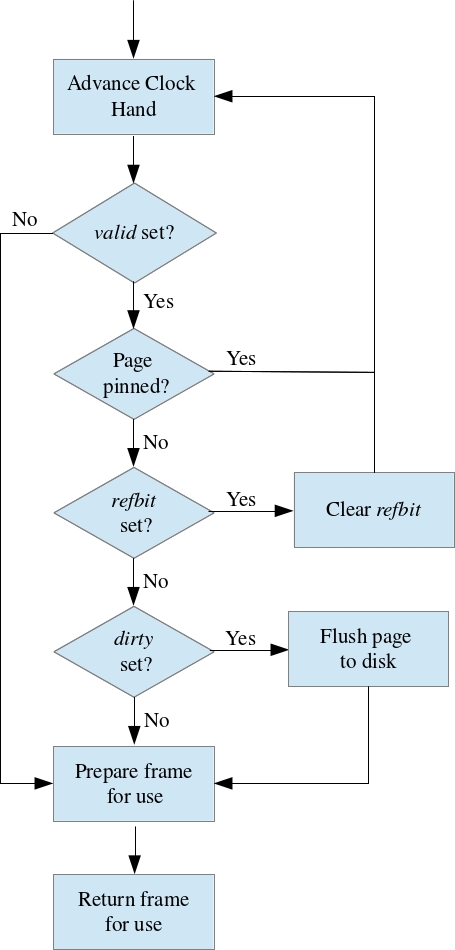
The algorithm is depicted in the flow chart to the right. At any point in time the clock hand (an integer whose value is between 0 and numFrames-1) is advanced in a clockwise fashion. If a page is not valid (i.e., unoccupied), it is an obvious candidate for replacement. Otherwise, we check to see if the page is still pinned since do not want to remove a page from the pool that is still being used. If a page is not in use, we resort to the refbit to approximate our LRU algorithm. If the refbit is true, the page has been recently unpinned and gets a "free pass" (i.e, set the bit to false and move on). Otherwise, we have found a replacement. If the selected buffer frame is dirty (i.e., it has been modified), the page currently occupying the frame is written back to disk. Regardless, the frame is cleared and the requested page from disk is read in to the freed frame. Further details are available below.
The WiscDB buffer manager uses three C++ classes: BufferManager, Frame and BufferHashTable. There is only one instance of the BufferManager class. A key component of this class is the actual buffer pool which consists of an array of numFrames frames, each the size of a database page. In addition to this array, the BufferManager instance also contains an array of numFrames instances of the Frame class that is used to describe the state of each frame in the buffer pool. A hash table is used to keep track of the pages that are currently resident in the buffer pool. This hash table is implemented by an instance of the BufferHashTable class. This instance is a private data member of the BufferManager class. These classes are described in detail below.
BufferHashTable
The BufferHashTable class is used to map file and page numbers to buffer pool frames and is implemented using chained bucket hashing (separate chaining). You must complete this implementation using the provided definition. The key structure is a HashItem, which stores one item in the hash table (similar to a node in a linked list). This points to a file (File *) and stores the page number (PageId) in the file (these two combine to form the key). The HashItem also stores a frame number (FrameId) (the value associated with the key) to recover the page from the buffer pool. Lastly, the next pointer is used to implement separate chaining; the item points to the next HashItem in the bucket.
You have been provided a hash function as well as a constructor. Do not modify either, but instead read and understand how the work. You will need to complete the implementation for the destructor, insert, lookup, and remove methods as explained in the documentation (either the header file or document web page). Pay attention to corner cases (e.g., empty buckets) as well as the exceptions you will need to throw for errors.
Frame
The Frame class is used to keep track of the state of each frame in the buffer pool. It is defined as follows:
First notice that all attributes of the Frame class are private and that the BufferManager class is defined to be a friend. While this may seem strange, this approach restricts access to Frame's private variables to only the BufferManager class. The alternative (making everything public) opens up access too far.
The purpose of most of the attributes of the Frame class should be pretty obvious. The dirty bit, if true indicates that the page is dirty (i.e. has been updated) and thus must be written to disk before the frame is used to hold another page. The pinCnt indicates how many times the page has been pinned. The refbit is used by the clock algorithm. The valid bit is used to indicate whether the frame contains a valid page. You you will need to implement the basic methods of the class (i.e., reset() and load()), just to ensure understanding of the purpose. reset() is invoked when a Frame is emptied and should reset all class variables to a default state. Note that rather than inventing your own constants for invalid states, you should take a look at the documentation to see if any constants have been defined already. For example, the Page class has defined a variable to indicate invalid page numbers (Page::INVALID_NUMBER). Also, the FrameId does not change for an individual frame; this should only be modified by the BufferManager.
load() is invoked after a page has been assigned to a frame; this method should set all member variables appropriately. This method is utilized for a new Page being loaded into the frame, so its pin count should be set to 1.
BufferManager
The BufferManager class is the heart of the buffer manager. This is where you write your code for this assignment. Note that, at a high level, the BufferManager manages a buffer pool of frames that contain pages. In the class definition, this is represented by two arrays: bufPool and frameTable. frameTable is the array of Frames that comprise the pool, holding meta information about each frame. The actual page being stored in a frame at a particular index (i.e., FrameId) is in the bufPool array. That is, if you would like to know the status the frame at FrameId 1, you access frameTable[1]. If you would like the Page stored at FrameId 1, you access bufPool[1]. As mentioned previously, hashTable is a directory that helps find a particular page in the pool quickly. That is, when checking the status of a certain Page object, we obtain it's FrameId by looking it up in the hash table.
Class Methods
This class is defined as follows:
- BufferManager(std::uint32_t bufs)
This is the class constructor. Allocates an array for the buffer pool with bufs page frames and a corresponding Frame table. The way things are set up all frames will be in the reset clear state when the buffer pool is allocated. The hash table will also start out in an empty state. I have provided the constructor. - ~BufferManager()
Flushes out all dirty pages and deallocates all dynamically allocated class data. - void advanceClock()
Advance clock to next frame in the buffer pool. - void allocateFrame(FrameId& frame)
Allocates a free frame using the clock algorithm; if necessary, writing a dirty page back to disk. Throws BufferExceededException if all buffer frames are pinned. This private method will get called by the readPage() and allocatePage() methods described below. Make sure that if the buffer frame allocated has a valid page in it, you remove the appropriate entry from the hash table. - void readPage(File* file, const PageId PageNo, Page*& page)
There are two cases to be handled: the page is already in main memory or it is not. Use your hash table to help decide which is the case and then handle both scenarios:
Case 1: The specified page is not already in the buffer pool. You will need to find a buffer frame (i.e., call allocateFrame()) and then load the specified page from disk (i.e., file->readPage()). Be sure to fully update the buffer pool meta-data, including insert the page into the hash table, storing the page in the buffer pool, and invoking load() on the frame to set it up properly. Return a pointer to the page now stored in the buffer pool via the page parameter.
Case 2: the specified page is in the buffer pool. In this case, you simply need to update the pin count for the frame, and then return a pointer to the page stored in the buffer pool via the page parameter. - void unPinPage(File* file, const PageId PageNo, const bool dirty)
When a higher-level query no longer needs a page, it releases its pin on the page. The buffer manager decrements the pin count of the frame holding the given page. If the pin count hits 0, you should set the refbit. The input parameter dirty indicates whether the page was modified and should correspondingly set the dirty bit for the frame to true if it was modified. Note that once dirty, a page stays dirty until it is flushed to disk, so do not set the dirty bit to false here. The method should throw PageNotPinnedException if the pin count is already 0. The method should allow the hash table to throw an exception if the page is not in the hash table (this is done by lookup, just ensure you do not catch that exception here). - void allocatePage(File* file, PageId& PageNo, Page*& page)
This method asks the buffer manager to handle a low-level disk allocation of space to hold a page. It should first rely on the File interface to handle the actual disk allocation (see allocatePage in the File). In addition to allocating a page on disk, the buffer manager must place this new page in the buffer pool (similar to Case 1 for readPage above). The method returns both the page number of the newly allocated page (see the Page interface to determine how to retrieve this) and a pointer to the page itself. - void disposePage(File* file, const PageId pageNo)
This method deletes a particular page from file. Before deleting the page from file, make sure that if the page to be deleted is in the buffer pool, that frame is emptied and correspondingly entry from hash table is also removed. - void flushFile(File* file)
When a query is completely done with using a file (e.g., did a full scan of all records), it may choose to tell the buffer manager that the file is no longer needed. This method should scan the buffer pool for pages belonging to the file. For each page encountered it should:- write dirty pages to disk
- remove the page from the hash table (whether the page is clean or dirty)
- empty (i.e., reset) the Frame holding the page in the buffer pool
- BufferStats: you can ignore this for now---you do not need to implement this for the lab 1 assignment.
Keep these style and testing guidelines in mind:
- We have defined this project so that you can understand and reap the full benefits of object-oriented programming using C++. Your coding style should continue this by having well-defined classes and clean interfaces.
- The code should be well-documented, using Doxygen style comments.
- Each file you are assigned to modify should start with your names and student ids, and should explain the purpose of the file.
- Each function should be preceded by a few lines of comments describing the function and explaining the input and output parameters and return values.
- Search for TODO statements in the documents for help navigating implementation requirements. Remember to delete this when "DO" them.
- You should thoroughly test your program. This includes adding tests to main.cpp. You can also add your own main with test code (you are not required to do so). If you do, you will need to update the Makefile to process each test file separately - see the Makefile comments for suggestions on how to do this.
- The tests I have provided are not designed to pinpoint specific errors. They are not very useful as debugging tools - you should add private methods, print statements, and gdb sessions to augment the tests.
- The tests I have provided are not exhaustive of all requirements. You should add harder tests for requirements not covered.
- With all implementations, you are allowed and encouraged to add private methods. However, you are forbidden from adding data members, public methods, and/or changing the access of provided data and methods.
Much of the code base was provided and developed by the University of Wisconsin Database Group.
Before the Due Date, push your solution to github from one of your local repos to the GitHub remote repo. Only one of you or your partner needs to do this, but it doesn't hurt if you both do.
From your local repo (in your ~you/cs44/labs/Lab01-partner1-partner2 subdirectory)
make clean git add * git commit -m "our correct, robust, and well commented solution for grading" git push
If that doesn't work, take a look at the "Troubleshooting" section of the Using git page. Also, be sure to complete the README.md file, add and push it.