|
For
all experiments:
Seed Number=257
Sweeps=40,000
Threshold=.5
How we measured
the performance of the network: If the maximum activation of state
of the 10 outputs nodes corresponded to the correct data value, and the
activation was greater than the threshold, then the network was able to
correctly learn the right value for the given pattern.
Criteria for handling
digits: Digits were considered difficult if the network could not
identify at least 95% of the occurrences of the digit in the data set.
Criteria for handling
sets: Sets were considered difficult if the network could not identify
at least 90% of the digits in the set.
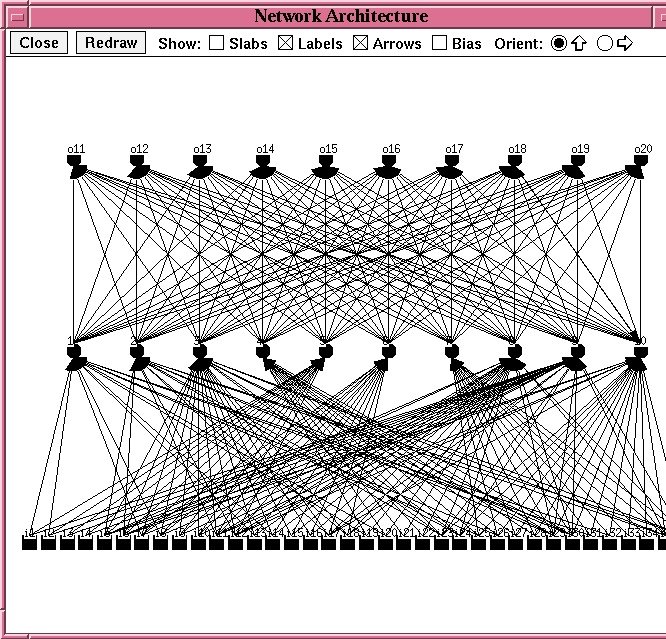
Control: Fully Connected Network
Results
For a fully connected network, the percentage of recognized digits is
94.6% (227/240).
Some of the numbers are harder to decipher than others, particularly 2,
3, 5 and 8 (could not identify at least 95% of the occurrences of the
digit in the data set)
Sets 1, 2, 15, and 16 were harder than the rest (could not identify at
least 90% of the digits in the set)
Experiment 1: Feature
Detector
Network Architecture: Feature Detector
Hypothesis: Looking at particular sections in the 6 by 6 matrix will allow
the neural network to decipher between numbers better.
Results:
For this network, the percentage of recognized digits is 94.6% (227/240).
Some of the numbers are harder to decipher than others, particularly 2,
5, 7 and 8.
Sets 1, 2, 3, 15, and 16 were harder than the rest
Conclusion: The feature
detector that we came up with did not perform better or worse than the
fully-connected network.
Discussion: We feel
that the fully-connected network was, over the training period, creating
its own feature detector system by modifying the weights between the inputs
and the hidden nodes. By doing this, it is effectively determining which
hidden nodes will pay attention to which parts of the matrix (each hidden
node will probably pay attention to what the network considers the most
salient parts of the matrix for this particular teaching set). We suspect
that over time the fully connected network may do better than our feature
detector. This is because the average error for the fully-connected network
decreased at a faster rate than the average error for our feature detector
between sweep 25,000 and 40,000. If in fact, the fully connected network
is constructing a feature detector, then it's constructing it systematically,
whereas our feature detector was constructed arbitrarily.
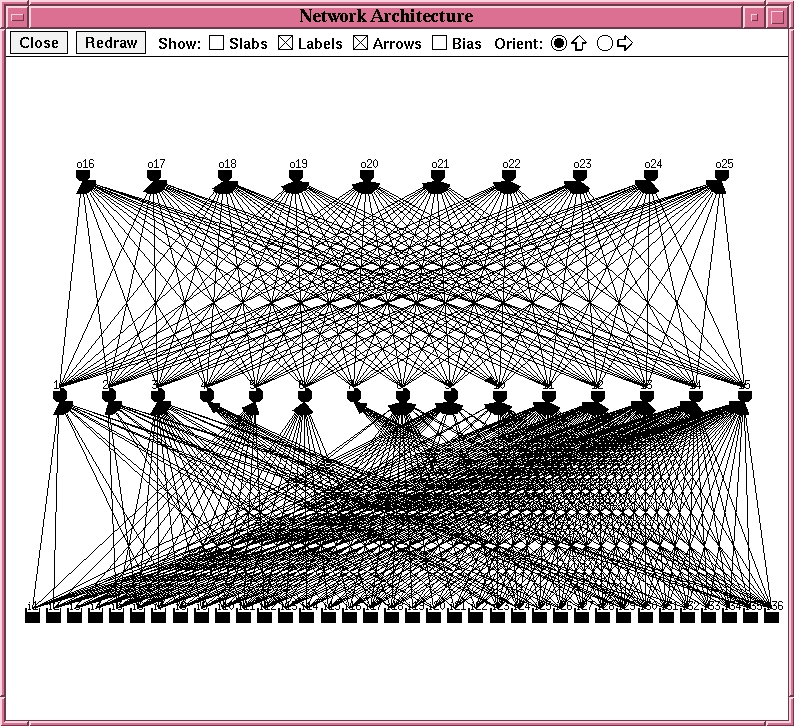
Experiment 2: Feature
Detector (10 nodes) with 5 fully-connected hidden nodes (single hidden
layer)
Network Architecture: Hybrid Network
Hypothesis: Since the fully connected network works pretty well, and since
the feature detector can deal with some numbers that the fully connected
network cannot deal with, then perhaps combining the first two ideas will
get us a better neural network.
Results:
For this network, the percentage of recognized digits is 97.1% (233/240)
Some of the numbers are harder to decipher than others, particularly the
number 2.
Sets 15 and 16 were harder than the rest
Conclusion: This hybrid
network worked better than the fully-connected network and the feature
detector.
Discussion: Perhaps
this network did better because it had more hidden nodes. Therefore, it
could create more feature detectors than either of the previous two networks.
Perhaps a fully connected network with 15 hidden nodes might outperform
the fully-connected, the feature detector and the hybrid neural networks.
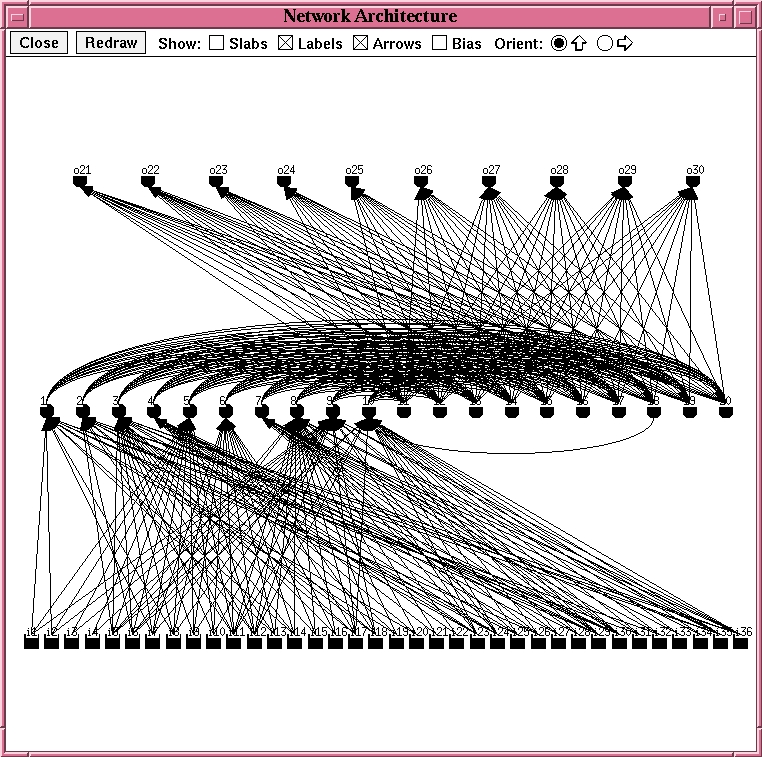
Experiment 3: Feature
Detector (layer 1) with 10 fully-connected hidden nodes (layer 2)
Note: The second layer is fully connected to layer 1 and the output layer,
not the inputs.
Network Architecture: Double-Layer Network
Hypothesis: Perhaps two layers is better than one. And since the hybrid
did so well before, perhaps we should incorporate those ideas as well.
Results:
For this network, the percentage of recognized digits is 93.8% (225/240)
Some of the numbers are harder to decipher than others, particularly the
number 0, 5, 6, and 9.
Sets 2, 15 and 16 were harder than the rest
Conclusion: This network
did worse than all the other networks.
Discussion: We can
refine our ideas earlier about the benefits of more hidden nodes to say
that extra hidden nodes should be included on a single level. Perhaps
a double-layer neural network is not suitable for a problem like this,
or perhaps this specific double layer (with feature detection on one level
and full-connections on the second) is not suitable for this problem.
Having two level probably confused the neural network (because two layers
of weights had to be changed for each sweep rather than one).
Summary of Results
| Experiment
|
Description |
Performance
(%) |
Difficult
Numbers |
Difficult
Sets |
Clustering |
| Control |
fully
connected |
94.6 |
2,3,5,8 |
1,2,15,16 |
there
were distinctive large clusters for 1,2,5,6. there were smaller and
numerous clusters of 0,4,7,8 and 9. there were mixed clusters of 0/6/8/2,
7/2, 3/7, 4/9, and 3/9. |
| 1 |
feature
detector |
94.6 |
2,5,7,8 |
1,2,3,15,16 |
clustering
was clean for 1,5,6, and 3. There were some mixed clusters and they
consisted of the numbers 0, 2, 7, and 8. Hidden node activations were
similar for 4/9 and 2/7. |
| 2 |
hybrid |
97.1 |
2 |
15,
16 |
surprisingly,
clustering for this neural network was not very distinct. there were
many small clusters and also mixed clusters. we were unsure of why this was the case. |
| 3 |
two
layers |
93.8 |
0,5,6,9 |
2,15,16 |
there
were two large mixed clusters . Distinct clusters included 0,1,2,4,6.
Smaller distinct clusters included 3,5,6,and 9. Hidden node activations
were similar for 4/9 and 2/7 |
BEST NETWORK:
The best network was the hybrid neural network (Experiment 3). It had
a higher performance rating, and was able to handle the difficult numbers
and sets that the other networks could not. We feel that this was better
than the others because it had more nodes than the others and was allowed
to create its own feature detectors over time. Another reason the hybrid
performs better than the feature detector is perhaps because a fully connected
network can learn more quickly than one in which the connections between
hidden nodes and inputs are limited.
|
|
{kind=link}
{kind=link}
{kind=link}