


Next: Topic: Learning to
Up: Lecture plans
Previous: Lecture plans
Terminology
- Neural networks: Focuses on the inspiration from the brain.
However most simulated networks are not that similar to biological
networks.
- PDP: Implies a particular style described in Rumelhart and
McClelland's books [7][6][8], so is not general enough.
- Connectionism: Generally the preferred term.
Characteristics of Biological Networks
- Human brains contain 10^10 to 10^11 neurons
- These neurons are densely interconnected with up to 10^5 connections per neuron
- Connections can be excitatory or inhibitory
- Learning involves modifying synapses
- Elimination and addition of connections can occur
Characteristics of Connectionist Networks
- Neurally inspired: slow and parallel, highly interconnected,
learning is done by changing the strengths of connections, processing
is distributed and decentralized
- Neuron is the basic processing unit
- Configuration of connections is the analog of a program
- Local computation produces global behavior
- Long-term memory is in the strengths of the connections
(i.e. the weights)
- Short-term memory is in the pattern of activity
Appeal of Connectionist Models
- Learning is fundamental
- Solutions are emergent
- Graceful degradation
- Spontaneous generalization
- Mutual satisfaction of multiple constraints
Brief History
- Brain-style computation began to be explored in the 1940s by
McCulloch, Pitts and Hebb
- Early work in AI was done within two competing models: parallel,
brain-like systems versus symbol processing on von Neumann machines
- Initially there were no learning procedures for multi-layer
networks and single layer networks were quite limited in what
functions they could approximate
- In part because of this the symbol processing approach became
the dominant view
- In the 1980s there was a resurgence of interest in neural
networks because of the popularization of the back-propagation
learning algorithm for multi-layer networks
- A multi-layer network can theoretically approximate any function
if given enough hidden units
- Although there is no guarantee that back-prop's gradient descent
method will avoid local minima, in practice it has proved successful
in a wide variety of applications including credit card fraud
detection, cursive handwriting recognition, loan approval, financial
forecasting, speech recognition, and robot control
Specifying a connectionist network
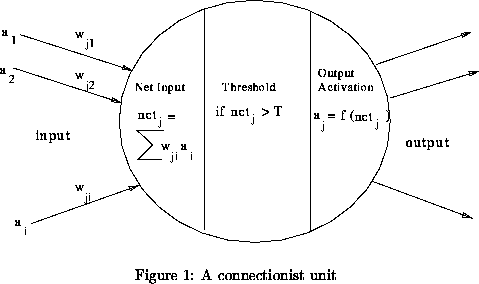
- Node characteristics, see Figure 1
- Topology
- Learning rule

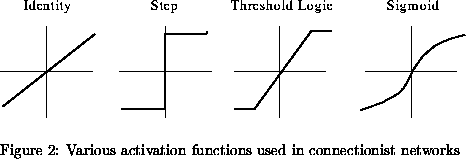
Architectures (simplest to most complex)
- Linear: feed-forward, one-layer, identity
activation function (see Figure 2)
- Perceptron: feed-forward, one-layer, step
activation function
- Backward-Propagation: feed-forward, multi-layer, sigmoid
activation function
- Recurrent: feedback and lateral connections, multi-layer,
non-linear activation function
- Constraint-satisfaction: symmetrical connections, no true
layers, non-linear activation function
- Arbitrary: anything goes, hard to analyze
Some examples
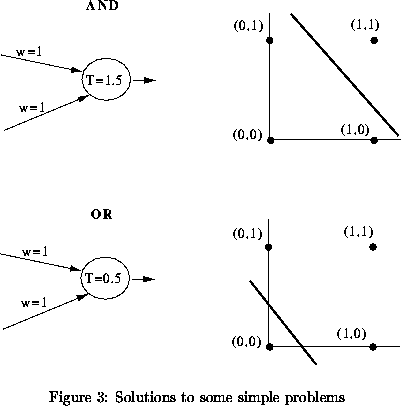
For some simple problems it is relatively easy to determine an
appropriate set of weights and thresholds without doing any learning.
For example consider the AND and OR problems shown below in
Figure 3.
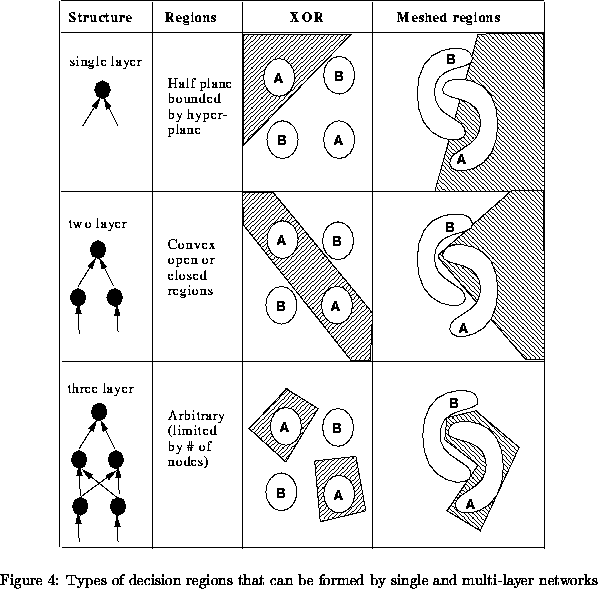
Notice that a single layer network which uses the step activation
function forms two decision regions separated by a hyperplane. The
position of this hyperplane depends on the connection weights and
threshold. Thus if the inputs from two classes are separable
(i.e. fall on opposite sides of some hyperplane) then there exists a a
single layer network to correctly categorize the inputs. However if
the inputs are not separable, a single layer network is not sufficient.
In particular a single layer network will not be able to solve the XOR
problem because a combination of decision regions are needed.
Figure 4 shows the kinds of regions that can be formed by
multi-layer networks.
Next: Topic: Learning to
Up: Lecture plans
Previous: Lecture plans