You should have a github repo ready to go by the time lab starts. Please let the instructor know if you have any issues accessing it.
In this lab we will apply deep Q-Learning to two reinforcement learning problems. We will use problems provided by Gymnasium.
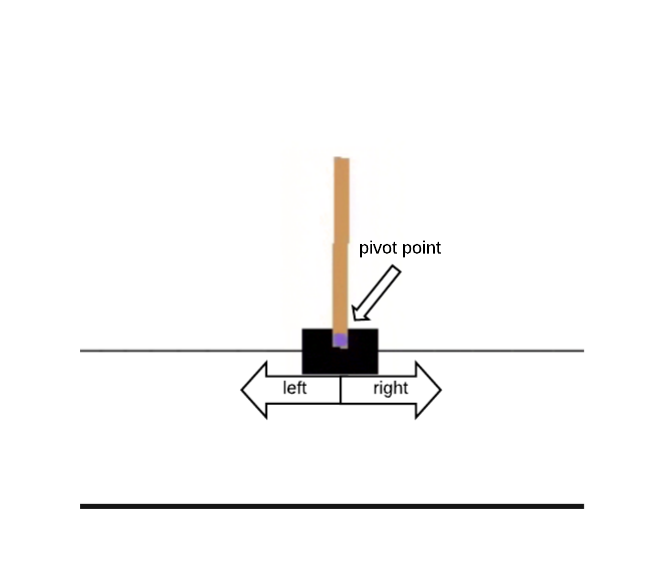
To start, we will focus on a classic control problem known as the Cart Pole. In this problem, we have a pole attached to a cart and the goal is the keep the pole as close to vertical as possible for as long as possible. The state for this problem consists of four continuous variables (the cart position, the cart velocity, the pole angle in radians, and the pole velocity). The actions are discrete: either push the cart left or right. The reward is +1 for every step the pole is within 12 degrees of vertical and the cart's position is within 2.4 of the starting position.
Once you've successfully been able to learn the Cart Pole problem, you will tackle a harder problem, the Atari game called Atlantis.
Open the file testGym.py and see how to create a gym environment, run multiple episodes, execute steps given a particular action, and receive rewards.
In order to use gymnasium, you'll need to activate the CS63 virtual environment. Then you can execute this file and watch the cart move and see example state information:
source /usr/swat/bin/CS63env
python3 testGym.py
Try the other environment, the Atari game Atlantis, which was initially commented out.
NOTE: this program tries to open a graphical window for output, which means it won't work well over a remote connection without doing some extra work. It should at least run regardless, but if you want to see anything you'll need to set up X-forwarding, by passing the '-X' flag to SSH, and also having an X-server running on your local computer. This happens automatically on Linux, but if you're on Windows or Mac there's some extra work to do if you want to run an X-server.
Generally, it's recommended to debug this program while actually sitting at a lab machine so you can see what it's doing.
Make sure you understand how this program works before moving on.
Recall that in deep Q-Learning we represent the Q-table using a neural network. The input to this network represents a state and the output from the network represents the current Q values for every possible action.
Open the file deepQCart.py. Much of the code has been written for you. This file contains the definition of a class called DeepQAgent that builds the neural network model of the Q-learning table and allows you to train and to use this model to choose actions. You should read carefully through the methods in this class to be sure you understand how it functions.
There are two methods that you need to write train and test. The main program, which calls both of these functions, is written for you and is in the file cartPole.py.
Here is pseudocode for the train function:
initialize the agent's history list to be empty
loop over episodes
reset the environment and get the initial state
state = np.reshape(state, [1, state size])
every 50 episodes save the agent's weights to a unique filename
(see program comments for details on this filename)
initialize total_reward to 0
loop over steps
choose an action using the epsilon-greedy policy
take the action, save next_state, reward, terminated, truncated
done = terminated or truncated
update total_reward based on most recent reward
reshape the next_state (similar to above)
remember this experience
reset state to next_state
if episode is done
break
add total_reward to the agent's history list
print a message that episode has ended with total_reward
if length of agent memory > batchSize
replay batchSize experiences for batchIteration times
if epsilon > epsion_min
decay epsilon
save the agent's final weights after training is complete
The test function is similar in structure to the train function, but you should:
And, you should not remember experiences, replay experiences, decay epsilon nor save weights.
To run this program for training with 200 episodes do:
python3 cartPole.py train 200
Remember that you will first need to activate the CS63env
in the terminal window where you run the code. Deep Q learning
should be able to find a successful policy in 200 episodes using the
parameter settings provided in the file.
Note: Reinforcement learning is significantly slower than supervised learning. Completing 200 episodes for the cart pole task may take 15-20 minutes.
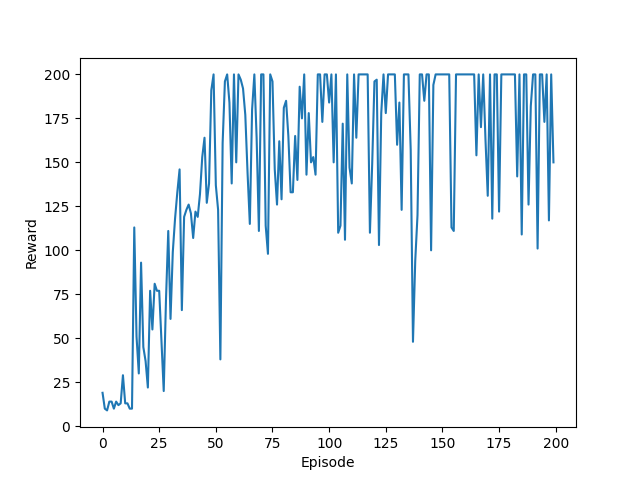
After training is complete, it is interesting to go back and look at the agent's learning progress over time. We can do this by using the weight files that were saved every 50 episodes.
To run this program in testing mode do:
python3 cartPole.py test CartPole_episode_0.weights.h5
This would show you how the agent behaved prior to any training at
episode 0. The next command would show you the behavior after 50
episodes of training.
python3 cartPole.py test CartPole_episode_50.weights.h5
The file CartRewardByEpisode.png contains a plot of reward
over time which also gives you a sense of the agent's progress on the
task. You can also view this file by doing:
eog CartRewardByEpisode.png
Do not move on to the next section until you have successfully
learned the Cart Pole problem.
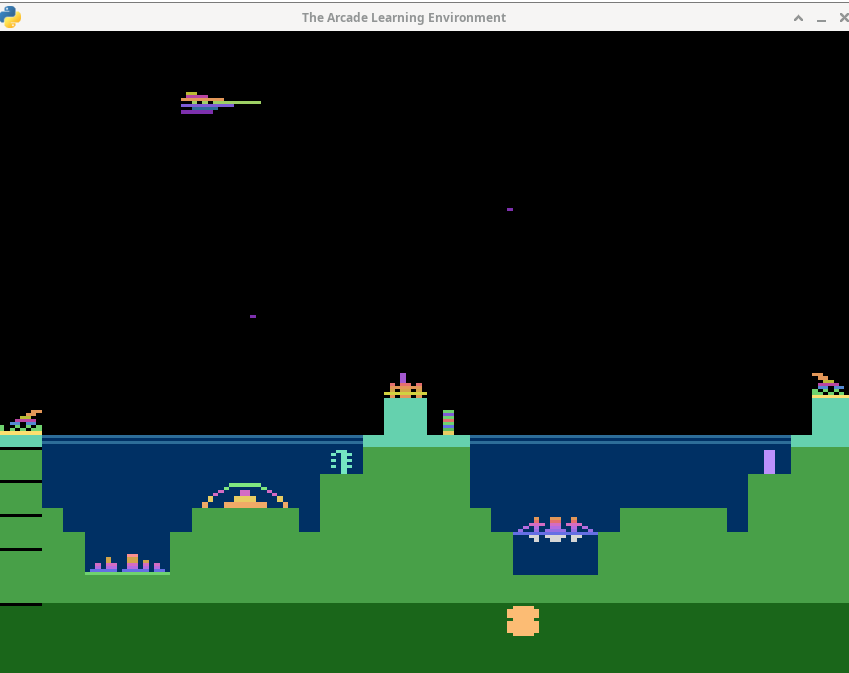
You will now try applying the same approach to a new problem called Atlantis (pictured below). This is a much harder problem, and you may not be able to solve it, but hopefully you can make some progress at finding a policy that is better than just randomly trying all of the actions.
The goal of this game is to defend the underwater city of Atlantis. You have three guns (left, center, and right) that you can fire to protect the city from the attackers above. Each enemy downed is worth points. You also receive bonus points for each part of the city that survives an attack wave.
You can try playing this game yourself. Note: The game will wait for a key press before it starts. Your cursor must be in the terminal window for the game to recognize key presses. Here's how to control the game:
To play the game do: python3 playAtlantis.py
As we have discussed in class, determining the appropriate settings for all of the hyperparameters in a machine learning system is a difficult problem. Luckily, the 2015 paper written by a collection of researchers at Deep Mind entitled Human-level learning through deep reinforcement learning describes their method of successfully applying approximate Q-learning to a large set of Atari games (including Atlantis). However, we may not have the processing power to duplicate all aspects of their approach.
Note: You may use any AI tools you'd like to help you on this portion of the lab. Just be sure to indicate what you used in your experimental_log file.
Finally, use git to add, commit, and push all of your files especially your graphs of rewards by episode and your movie!
The structure of the Q-learning algorithm is based on code provided at Deep Q-Learning with Keras and Gym