
The GridWorld implementation for this lab is based on one by John DeNero and Dan Klein at UC Berkeley.
The policies found for a particular gridworld are highly dependent on the reward function for the states. On the left, the living reward was 0 for every non-terminal state. In this case the policy from the start state (in the lower left corner) takes the northern route towards the positive terminal state. On the right, the living reward was -1 for every non-terminal state. In this case the policy from the start state takes the eastern route, willing to risk the negative terminal state.
As in the previous lab, use Teammaker to form your team. You can log in to that site to indicate your partner preference. Once you and your partner have specified each other, a GitHub repository will be created for your team.
In this lab, you will be exploring sequential decision problems that can be modeled as Markov Decision Processes (MDPs). You will begin by experimenting with some simple grid worlds implementing the value iteration algorithm.
The starting point code includes many files for the GridWorld MDP interface. Most of these files you can ignore. The only files you will modify are:
An MDP describes an environment with observable states and stochastic actions. To experience this for yourself, run Gridworld in manual control mode, and use the arrow keys to move the agent:
python3 gridworld.py -m
You will see a two-exit environment. The blue dot is the agent. Note that like in lecture each action you try only has its intended outcome 80% of the time, while 10% of the time it will go off in either of the orthogonal directions.
You can control many aspects of the simulation. A full list of options is available by running:
python3 gridworld.py -h
You can try controlling the agent manually on another grid world:
python3 gridworld.py -m -g MazeGrid
Note: The Gridworld MDP is such that you first must enter a pre-terminal state (the double boxes shown in the GUI) and then take the special 'exit' action before the episode actually ends (in the true terminal state called TERMINAL_STATE, which is not shown in the GUI). Part of the reason for this is that this version of Gridworld give rewards for (state, action) pairs instead of for states.
Look at the console output that accompanies the graphical output. You will be told about each transition the agent experiences (to turn this off, use -q).
Positions are represented by (x,y) Cartesian coordinates and any arrays are indexed by [x][y], with (0,0) at the bottom-left corner. By default, most transitions will receive a reward of zero, though you can change this with the living reward option (-r).
An MDP can be 'solved' using value iteration. It works by performing repeated updates until value estimates converge. Your first task is to complete the ValueIterationAgent in the file valueIterationAgents.py. Pseudocode is available on the lecture slides.
The ValueIterationAgent takes an MDP on construction the calls the valueIteration function, which you will implement. You will also need to implement the getPolicy function, which takes a state and returns the best action at that state (according to the values stored by value iteration).
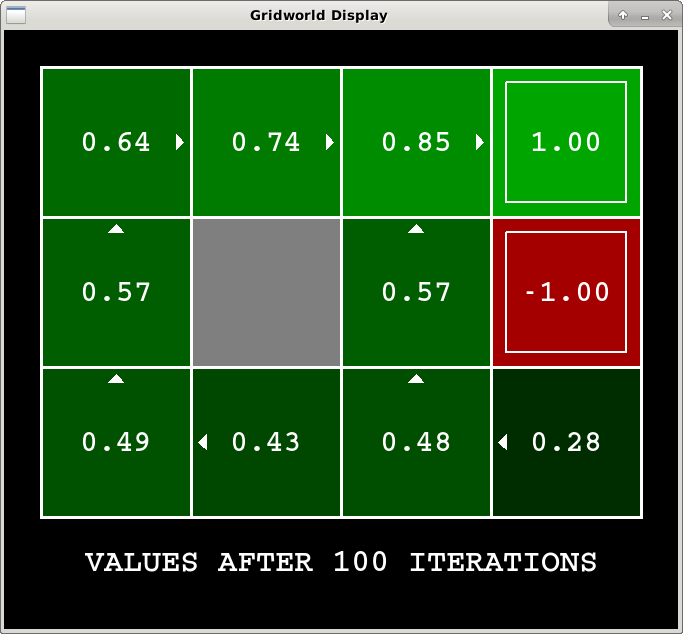
Once you have implemented these functions, you can use the following command to display the 100-iteration values computed by your agent:
python3 gridworld.py -i 100
The expected value of a state depends on a number of factors including how future rewards are discounted, how noisy the actions are, and how much reward is received on non-exit states. Find appropriate settings for these variables in the following scenarios and record what you find in the analysis.txt file.
python3 gridworld.py -i 100 -g BridgeGrid --discount 0.9 --noise 0.2
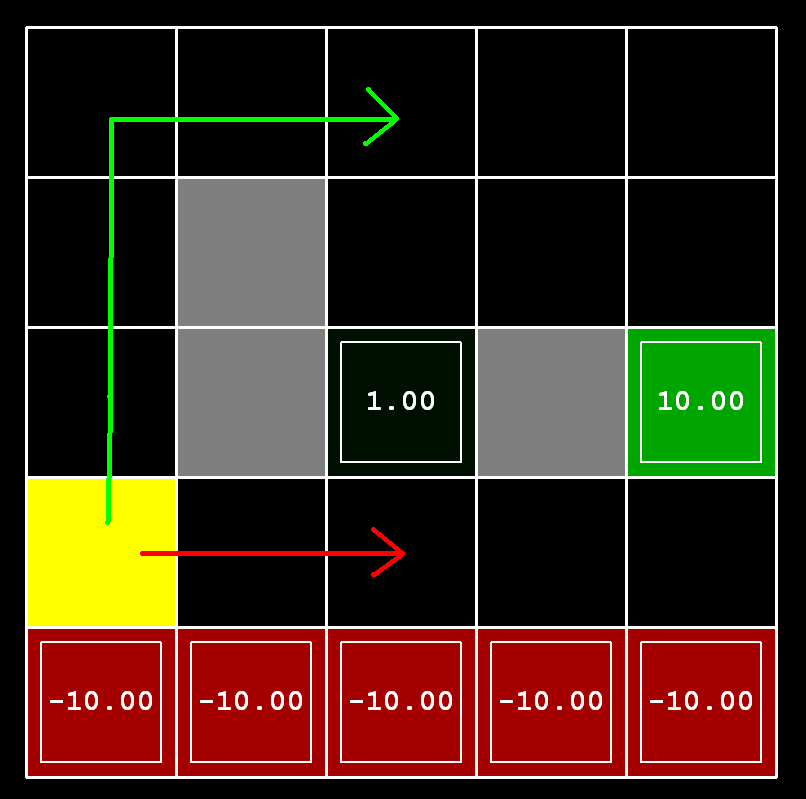
Give an assignment of parameter values for discount, noise, and livingReward which produce the following optimal policy types or state that the policy is impossible. The default corresponds to:
python3 gridworld.py -i 100 -g DiscountGrid --discount 0.9 --noise 0.2 --livingReward 0.0
python3 gridworld.py -i 100 -g MyGridYou should provide a grid that gives the agent interesting decisions to make. That is, there should be multiple possible paths to terminal states, and the optimal behavior should change under some environment settings. In analysis.txt you should provide a description of your MyGrid implementation and an explanation of how changing parameters like discount, noise, and living reward changes the optimal policy.
Be sure to use git to add, commit, and push the files that you modified.