CS 45 — Lab 5: Building a File System
|
If you are in a position in which you can reliably meet with your partner to work on the lab, please plan to demo your FS during the Friday timeslot. Not all of your classmates may be so lucky. If you need to demo on Tuesday (after class time), please make an appointment with me via email at least one day in advance. |
Checkpoint 1 Meetings: Friday, April 10 or Tuesday, April 14
Checkpoint 2: Friday, April 17 or Tuesday, April 21
Due: Monday, May 4 @ 11:59 PM
1. Overview
You’ve probably taken file systems for granted your whole life: you click save, and the file is safely stored on the disk for you to retrieve later. For this lab, you’ll develop your very own file system so you can see what goes in to making that "save" work. Unlike a real FS though, we’ll be focusing only on correctness rather than performance too. It’s difficult enough making the FS be reliable!
To interface with the OS, we’ll use the File
System in Userspace (FUSE) library, which allows you to write a userspace
program that manages files and integrates them into the OS’s file structure.
That is, when your userspace program is running, you’ll be able to interact
with your file system from the terminal using standard commands (ls, mkdir,
rm, etc.). FUSE is the same mechanism that
SSHFS uses to provide files over an SSH
connection.
To mount your file system, you’ll need to choose a location in the system’s
file tree to "graft" your files. Because of the way FUSE works, you cannot
mount on top of an NFS file system (unless you’re the root user, which you
aren’t). Thus, you will not be able to mount within your home directory.
Luckily, you still have /local available to you. I would suggest making a
new empty directory in /local: /local/fuse-username to use for testing. To
be clear, you can still store, edit, build, and run your swatfs code from
your home directory. When you execute it, you need to tell it to mount your
files in a non-NFS location like /local.
You can mount the FS with this command:
# The -o direct_io, -d, and -s are FUSE parameters: # -o direct_io - disable kernel caching # -d: debug mode - provide output about the operations that are happening # -s: single-threaded mode - you probably don't want to worry about concurrency right now... ./swatfs -o direct_io -d -s /local/fuse-username [disk image]
Replace the "fuse-username" above with the directory you created in /local for
testing. The disk image will be the path to a file that represents a "disk"
that has been formatted with the swatfs format. I’ve provided an example disk
image, named test-disk.img that is pre-populated with a few directories and
files. Use this to test your FS’s read functionality before you have writing
implemented.
|
A disk "image" is a file that contains all of the information needed by a SwatFS file system. That is, it holds FS metadata, file metadata, and file blocks. It is not an "image" like a viewable picture. The |
Later, you can create a new empty disk image with a combination of dd and
swatfs_mkfs:
# Create a 100-block disk image file, named disk.img, with a block size of 4096 bytes. dd if=/dev/zero of=disk.img bs=4096 count=100 # Format the file system for use with swatfs: ./swatfs_mkfs disk.img
If you break a file system image (e.g. you attempt to write and something goes
wrong), you can always reformat it with swatfs_mkfs to bring it back to a
clean slate (no files, all blocks free, etc.). If you’re at a pre-write stage,
you can always grab a clean copy of the test-disk.img from the plain Lab5
repository on GitHub.
To unmount your file system, you want to cleanly remove it from the system’s
file tree. Don’t just Ctrl-C your swatfs program! Instead, run fusermount
-u /local/fuse-username. That should terminate your userspace process and
unmount the FS cleanly.
|
You need to be outside the FUSE-mounted directory to unmount the file system. If your |
1.1. Goals
-
Implement a small-scale, traditional file system using inodes, directory entries, and blocks.
-
Work with indirection in data structures.
-
Simulate a block-level disk interface with mmap().
1.2. Handy References
2. Requirements
|
The amount of code you’ll need to write for this lab is likely to be larger than previous labs in this course. Do NOT look at the three-week deadline and become complacent. You should start this lab early. |
2.1. Memory and Files
Your file system should free all memory and get a clean bill of health from
valgrind: no invalid memory accesses, uninitialized variables, or memory
leaks.
2.2. File System Operations
Your file system should support creating, reading, writing, and removing both
regular files and directories. It should correctly report file attributes
(e.g., if the user calls stat(), which triggers your FUSE getattr()). To
make all this happen, you should provide implementations for all of the empty
swatfs_ functions in swatfs.c. Ultimately, typical commands like ls,
cd, rm, rmdir, I/O redirection (< and >), and text editors should
all be able to interact with the files and directories in your file system.
When dealing with file attributes, you only need to worry about those that
exist in the struct inode defined in swatfs_types.h. For example, your FS
should properly update a file’s modification time, but it does not need to
worry about access time, since there is no access time field in your inode
struct.
2.3. Error Reporting
Your file system should detect errors when they happen, and when they do, set
errno and return an appropriate error value. It’s not feasible for me to
dictate every single possible error that might occur, so please choose error
constants that describe the error condition as closely as possible. You can
see a list of error constants using errno --list or search for specific words
using errno --search [word]. Try to be as specific as possible. For
example, if the user asks to remove a directory that isn’t empty, don’t use
EIO (I/O error), even though this is an I/O related problem, because
ENOTEMPTY is a much better fit.
When reporting an error, you typically want your function to set the errno
variable and then return a non-zero value. A common pattern I would recommend
is:
if (bad_thing_happens) {
errno = EBADTHING; // Set the errno variable for the caller.
return -errno; // Return a non-zero value that also encodes the error code.
}For some functions, the FS will only behave correctly if you report errors
appropriately. For example, when you run mkdir on the command line to create
a new directory, it will first check to see if a file already exists at the
specified location. For mkdir to proceed, that initial check must fail
with ENOENT (no such file or directory). Otherwise, it will never even
attempt to call swatfs_mkdir.
2.4. Data Structures and File Organization
You should use the data structures defined in swatfs_types.h without
modifying them. They’re designed to be a particular size that evenly divides
blocks. The function prototypes for the swatfs_ functions in swatfs.c are
dictated by the FUSE library, so it will fail to compile if you change those.
Otherwise, I don’t care too much how you structure things or where you put
code.
I would strongly suggest factoring out common functionality into helper
functions though. There are several places where functions have major overlap.
For example, the functionality for making a new file (swatfs_create) and
making a new directory (swatfs_mkdir) have a ton in common.
2.5. Constants and Assumptions
Your implementation should use the #defined constants from swatfs_types.h
when dealing with numerical constants, and it should continue to function
properly if those constants change. For example, don’t hardcode the number 4
when dealing with an inode’s block pointers — use SWATFS_DIRECTPTR instead.
The latter will be much easier to read and understand.
You may always assume:
-
The root directory (path "/") will always be described by the inode whose number is 0.
-
There will not be multiple hard links for a file. That is, for every inode in the system (other than inode 0, which is special), the
linksfield will be either 0 (inode is free) or 1 (inode is being used). It will not be larger than 1. -
No
pathparameter given to yourswatfs_functions will be larger than SWATFS_NAMELEN. -
There will be no gaps in the files you are asked to write. For example, if you have an existing file that is 100 bytes long (bytes 0 through 99), the user can ask to do a write starting at any offset from 0 through 100, where "100" means "add new data to the end of the file". They would not be allowed to request a write to an offset >=101 without first writing to 100.
-
Directories will not need to use indirect block pointers. That is, there will never be more than 64 entries in a directory when using a 4096-byte block size.
-
The size of a
struct inodeand the size of astruct direntwill evenly divide the size of a block. -
The type (as far as the OS and file system are concerned) of every file will be either regular or directory. You don’t need to worry about device files, FIFO files, symbolic links, or any other uncommon file types.
3. Checkpoints
Because this is a three-week lab, we’ll have two checkpoints.
3.1. Checkpoint 1: Reading
For the first checkpoint, your file system should be able to read directories
(e.g., ls should work) and read regular files. Your GitHub repository
contains a disk image named test-disk.img that I’ve pre-populated with a few
directories and files of varying sizes for testing purposes. You should be
able to list and read all of those. For the .jpg picture file, you can use the
eog application ("eye of GNOME") to open it from the command line.
Since reliability is paramount to a file system, you want the files you
retrieve to be byte-for-byte identical to the original that was saved. The
md5sum utility will give you a hash for a file. The hash for fiona.jpg
should be:
$ md5sum fiona.jpg 6caf8dcb87be607d4bc767d55df76252 fiona.jpg
|
It’s not enough for the picture to "look ok". It’s possible to get an image
that renders mostly correctly (such that a person can’t easily see a
difference) without a byte-for-byte identical file. If the image looks fine
but your |
3.2. Checkpoint 2: Writing Regular Files
For the second checkpoint, your file system should be able to write regular files. Since it isn’t required to be capable of creating new files yet, that test disk image will come in handy again, since you can append to or overwrite the existing file contents. I would suggest starting with simple I/O redirection commands to write files:
# Overwrite the contents of "small_file": echo "test string" > small_file # Append new text to the end of "small_file": echo "more text" >> small_file
When those simple tests succeed, you can move on to copying larger files from other locations (e.g., your home directory) into your file system. You should ultimately aim to test with files that are larger than 16384 bytes (to require the use of indirect blocks), but you don’t want to use giant files. Something in the 20 KB - 40 KB is ideal.
|
As you implement writing, it’s very likely that bugs in your write operation
will cause you to write an invalid file system. I would suggest keeping a
clean copy of the If need be, you can always recover the original |
4. Starter Code Map
This lab uses several source files to divide up the functionality across
logical boundaries. With the exception of the structs in swatfs_types.h,
you’re allowed to modify any code you’d like. That said, you probably only
need to make changes in swatfs.c and swatfs_directory.c:
-
swatfs.c: the main file that defines and implements the core file system functions. -
swatfs_directory.c: a place to put directory-related helper functions. You can use this, or not, I don’t really care. It has several examples of function prototypes that I found to be useful in my implementation. If you want to put everything inswatfs.c, I’m not going to stop you, but it might get cluttered…
While you’re allowed to modify the other files, I don’t think you’ll need to. They’re there to provide you with basic functionality like retrieving/storing data to the disk. The corresponding headers for each of these has more details about the functions, their arguments, and their return values:
-
swatfs_disk.c: provides functions to simulate low-level disk access: read a block or write a block by providing a block number. Note: these functions transfer an entire block. If you’re trying to just change a small portion of a block, you need to read the rest of the block first so that you don’t overwrite the pieces you’d like to keep.swatfs_inode.cdoes this when writing inodes, so take a look there for an example. -
swatfs_blockbitmap.c: keeps track of the status (free vs. in-use) of data blocks on the disk. You can query these functions to give you a free block or tell it to mark a block that you no longer need as free. -
swatfs_inode.c: allows you to read and write inode data by providing the inode number (inum). Also has a function for getting the inode number of the next free inode. -
swatfs_mkfs.c: this file won’t be used by your FS implementation directly. It defines a standalone program that formats a file to be used as a disk image. -
swatfs_types.h: defines structs for the key FS data structures you’ll be interacting with: inodes and directory entries. It also defines several important constants that will come up repeatedly in your implementation. The structures have been carefully designed to be appropriate sizes that evenly divide disk blocks, so you shouldn’t change the struct definitions!
With all the default settings, the block layout and inode block pointers will look like these figures:

|
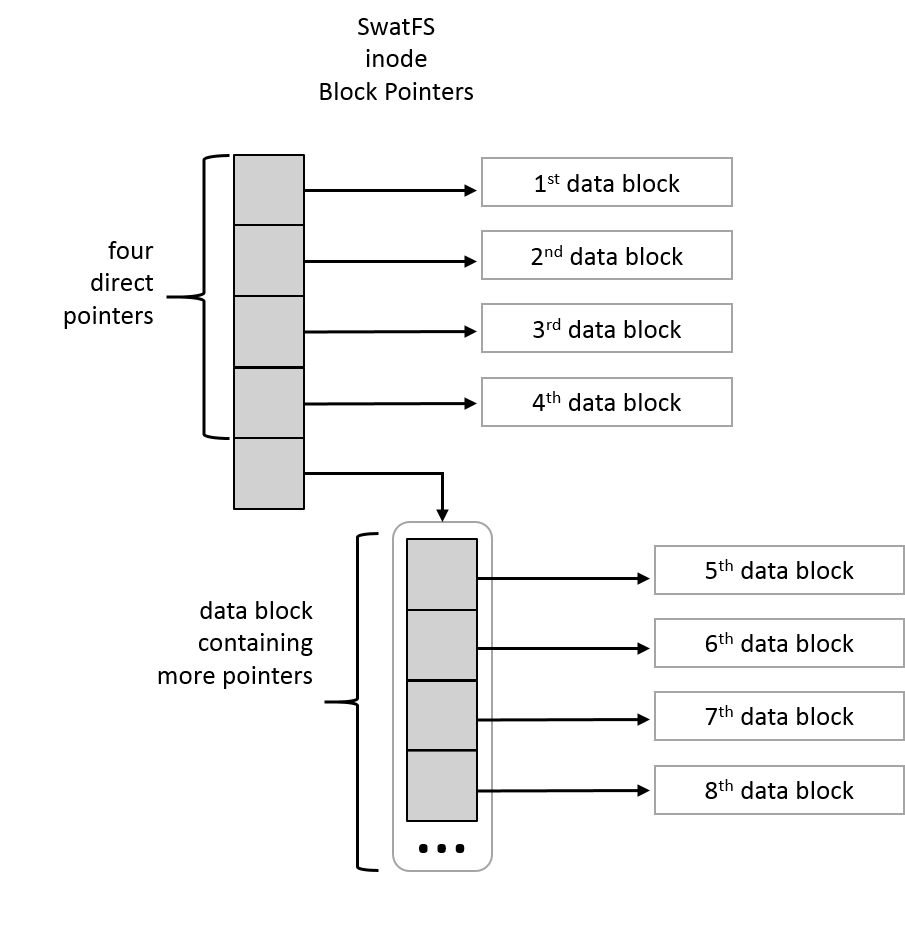
|
|
Block 0 is intentionally never used by our file system in an attempt to catch
errors. If you ever attempt to read or write block 0, your |
5. Getting Started & Function Order
The function for getting a file’s attributes, swatfs_getattr, gets called by
just about every other function that accesses the file system. Without it, you
can’t get much done. I would suggest starting by implementing that function,
which is largely just filling in the fields of a struct stat based on an
inode’s data. To start with, assume that directory_lookup is properly
filling in inode and inum for you — that will be the next function to work
on.
The directory_lookup function lives in swatfs_directory.c. It’s heavily
commented with suggestions for getting started, and it’s also used almost
everywhere, so you’ll also need it implemented before you can make any other
progress.
After those two are done, you’ll probably want to work on swatfs_readdir so
that you can list the files in the directory. After file listing works, you
can implement swatfs_read to retrieve file contents.
6. Tips & FAQ
-
Start early, and start testing as soon as you have enough functionality implemented to do so! It’s much easier to find bugs when only a few things have changed than it is to implement everything and then debug a larger code chunk later.
-
Factor out repeated functionality into helper functions. In some cases, there are pairs of functions that are extremely similar (e.g., rmdir and unlink). You can probably do most if not all of them both in one helper function.
-
When reading a block from the disk, you’ll often want to treat the block’s data differently depending on how you intend to use it. For example, if you know the block you’re reading will contain directory entries, you’d like it to be typed as such in the C type system. When declaring variables for data blocks, you can use the following tricks:
-
For directory entries, you can declare a block as:
struct dirent block[SWATFS_BSIZE / sizeof(struct dirent)]; -
For block pointers, you can declare a block as:
uint32_t block[SWATFS_BSIZE / sizeof(uint32_t)]; -
For generic user data, you can declare a block using characters:
char block[SWATFS_BSIZE];The implementation of
inodes.cuses this idea if you’d like to see an example.
-
-
FUSE’s
readdirfunction is a little weird. It gives you a "filler" that you can use to populate a buffer with names from the directory. For each name, callfiller(buf, name, NULL, 0). That should take care of formatting the output so that you don’t have to. -
The
modeattribute of a file encodes both the file’s type and its access permissions. You can call theS_ISREG()andS_ISDIR()macros on a mode field to test the file type. See the stat() manual for more details about the mode attribute. -
When you’re adding a new entry to a directory, make sure to initialize all the fields of the new inode, including the block map.
-
Some operations, particularly those that deal with adding or removing items in directories, will require you to divide a path into two parts: the name of the directory and the name of a file within that directory. I’ve provided two functions for you (
easy_dirnameandeasy_basename) at the top ofswatfs.cto make that operation easier. Note that after calling those functions, you’re responsible for freeing the memory they return to you. -
When you start up the
./swatfsprocess, something (the XFCE window manager?) always looks for a directory named ".Trash". You can safely ignore that lookup, it’s expected to fail, since there is no directory by that name in your file system.
7. Submitting
Please remove any excessive debugging output prior to submitting.
To submit your code, commit your changes locally using git
add and git commit. Then run git push while in your lab
directory.
8. Local VM Setup
If you’re testing the FS on a local VM rather than a CS machine, you can boot one of the default generic kernels.
You’ll need to install some packages in order to use FUSE and view pictures. Run this command once to add the necessary packages:
sudo apt-get install libfuse-dev eog