CS35 Lab 8: Analyzing web content with balanced binary search trees
Your work for this lab consists of two parts:
- Complete and test a templated implementation of an AVL tree, AvlTree.
- Use the AvlTree to build an index of user web pages hosted by www.cs.swarthmore.edu. Given a search query, use your AvlTree-based index to find web pages that match the search query.
As usual, you can get the initial files for this lab by running update35. When you run update35 you will obtain a large number of files for this lab, but you need to edit only four of them to complete this lab. The files that you will need to edit are highlighted below. Many of the files are from Lab 07 and are not listed here:
- avltree.h: Defines an AvlTree implementation of Lab 07's Bst interface.
- avltree.inl: Implements the AvlTree class.
- testAvl.cc: A program that tests your implementation of the AvlTree class.
- search.cc: A program to build an index of user web pages and find web pages that match search queries.
- swathtmlstream.h: Defines an iostream-like class that reads tokens from user HTML files hosted by www.cs.swarthmore.edu.
- swathtmlstream.cc: Implements the SwatHtmlStream class.
- testSwatHtmlStream.cc: A short program that demonstrates the SwatHtmlStream class.
- urls.txt: A text file listing some user web pages hosted by www.cs.swarthmore.edu.
- urls-short.txt: A shorter text file listing one user web page hosted by www.cs.swarthmore.edu.
- ignore.txt: A text file of words to ignore when building your index of web pages.
In the next section we introduce our AvlTree implementation. We then describe your main task (the search.cc program) and several specific tools you'll need to complete it.
You should start by completing and testing the AvlTree implementation. The AvlTree is very similar to the LinkedBst from Lab 07, except it maintains the AVL balance property to guarantee that the tree is balanced. (The AVL balance property is that, for each node in the tree, the height of that node's left and right subtrees differs by at most one.)
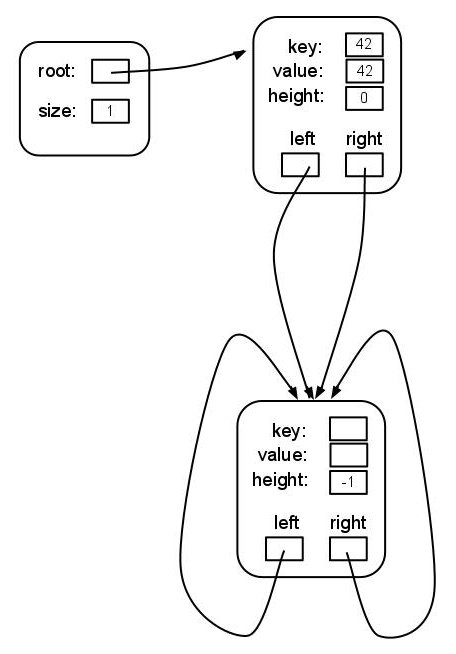
To efficiently maintain the AVL property, each AvlTreeNode stores its current height in addition to the other data stored by a LinkedBstNode. In sum, each AvlTreeNode contains:
- key: The key stored in this node.
- value: The value stored in this node.
- height: The current height of this node.
- left: A pointer to the left subtree of this node.
- right: A pointer to the right subtree of this node.
Our AvlTree has one representational oddity: instead of representing an empty tree as a NULL pointer we define a special node, AvlTreeNode<K,V>::EMPTY_TREE, to represent an empty tree. The EMPTY_TREE is just a node with height -1 and left and right child pointers back to itself:
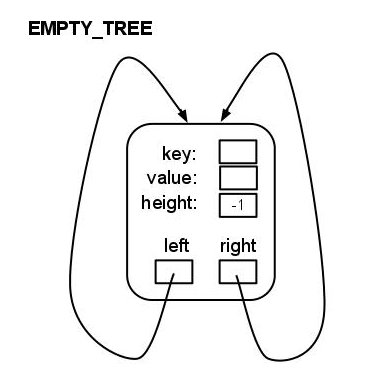
To complete the AvlTree, you should complete each of the rotation functions marked TODO in avltree.inl. There is one rotation function for each of the four cases discussed in class:
- singleRotateRight: rebalances the tree when an unbalanced node's left-outer grandchild is too tall.
- doubleRotateRight: rebalances the tree when an unbalanced node's left-inner grandchild is too tall.
- singleRotateLeft: rebalances the tree when an unbalanced node's right-outer grandchild is too tall.
- doubleRotateLeft: rebalances the tree when an unbalanced node's right-inner grandchild is too tall.
You should test the AvlTree implementation using the testAvl program. Ideally, your tests should confirm that each of your rotation functions behaves as expected for known examples of the tree, and also stress test the AvlTree implementation for a large number of random insertions and deletions.
You should write whatever tests are needed to evaluate your work, but you do not need to test other AvlTree functions that we provided for you.
Your main work for this lab is to write a search program, inside search.cc that analyzes www.cs.swarthmore.edu web pages and allows a user to find pages that match a search query. This program should take two command-line arguments:
- urls-file: a file of www.cs.swarthmore.edu URLs (whitespace-separated) to analyze.
- ignores-file: a file of search terms to ignore (also whitespace-separated)
Your program should do the following:
- Open and read the ignores-file, saving each word in the file into a tree containing all words to ignore when searching web content.
- Open and read the urls-file. For each URL in the file, use the SwatHtmlStream to read the web page for that URL, creating an index of the word frequencies for that web page. In your indexes do not include any words contained in the ignores-file.
- Using standard input and output, allow the user to search for terms in the web pages. For each search term, display the URL of each page containing the term and the number of occurrences of the term in that web page.
$ ./search urls.txt ignore.txt
Enter your search query: sleep
Searching for "sleep":
www.cs.swarthmore.edu/~charlie/cs21/f10/Labs/lab04.php: 1
www.cs.swarthmore.edu/~charlie/cs21/f10/Labs/lab05.php: 1
www.cs.swarthmore.edu/~charlie/cs21/s11/Labs/lab05.php: 3
www.cs.swarthmore.edu/~charlie/cs21/s11/Labs/lab06.php: 4
Enter your search query: time
Searching for "time":
www.cs.swarthmore.edu/~charlie/cs21/f10/Labs/lab04.php: 1
www.cs.swarthmore.edu/~charlie/cs21/f10/Labs/lab05.php: 1
www.cs.swarthmore.edu/~charlie/cs21/f10/Labs/lab06.php: 3
www.cs.swarthmore.edu/~charlie/cs21/f10/Labs/lab07.php: 1
www.cs.swarthmore.edu/~charlie/cs21/f10/index.php: 6
www.cs.swarthmore.edu/~charlie/cs21/s11/Labs/lab05.php: 1
www.cs.swarthmore.edu/~charlie/cs21/s11/Labs/lab06.php: 2
www.cs.swarthmore.edu/~charlie/cs21/s11/Labs/lab07.php: 3
www.cs.swarthmore.edu/~charlie/cs21/s11/index.php: 6
www.cs.swarthmore.edu/~charlie/cs35/f11/index.php: 1
www.cs.swarthmore.edu/~charlie/cs35/f11/labs/lab01.php: 3
www.cs.swarthmore.edu/~charlie/cs35/f11/labs/lab03.php: 8
www.cs.swarthmore.edu/~charlie/cs35/f11/labs/lab04.php: 23
www.cs.swarthmore.edu/~richardw/index.html: 1
Enter your search query: the
Searching for "the":
Enter your search query: <CTRL-D>
$
Lab 04 apparently mentions time a lot. The word "the" is not found
for any documents because it is in our default ignore.txt file.
You should add words to ignore.txt that you think should be
ignored when building the web index.
For each URL you should build a tree to store the frequency
of each word in the web page; each of these trees will probably have a
type such as AvlTree<string,int>. But wait, there's more!
You will also need a method to associate each URL with its word-frequency
tree. One way to accomplish this is...with another tree! For instance,
you could use each URL as a key, and a pointer to the URL's word-frequency tree
as the value. This might have the type
Below we give some specific advice for this lab, including how to read command-line arguments in C++, how to use C++ file streams and the SwatHtmlStream, and how to create your own web page for testing purposes.
To process command-line arguments in C++ you need to add two arguments to your main function:
int main(int argc, char** argv) {
// ...
return 0;
}
argc is an int representing the number of arguments entered
(including the program name itself), and argv is an array of
character arrays, with each character array containing one argument to
the program. (These variables can be called anything you want, but
it's a long-standing convention to call them argc and argv.)
You can then use argc and argv inside your program to
access the command-line arguments.
We've been using cin and cout to get input from and display output to the user, but cin and cout are just two example input and output streams in C++. In this lab you will create and use an input stream to read from a file, much like we've read input from cin. For example:
#include <iostream>
#include <string>
#include <fstream>
using namespace std;
int main(int argc, char** argv) {
ifstream myFile("urls.txt");
if (!myFile.good()) {
cerr << "Whoops! We couldn't open urls.txt.\n";
return 1;
}
string url;
myFile >> url;
while (!myFile.eof()) {
cout << url << endl;
myFile >> url;
}
myFile.close();
return 0;
}
To use a file stream you must include the fstream library.
This program creates a file input stream, myFile, to read from the
file urls.txt. It then checks that the input stream is valid (i.e.,
that the file exists and is readable), and then uses the input stream to
read each input from the file. At the end of the file, the program closes
the file and exits.
This program also demonstrates cerr, another output stream like cout. The usual convention is to use cout for standard output when the program is normally executing, but to use cerr for unusual output such as error messages.
For this lab we have also provided SwatHtmlStream, a stream-like class that allows you to read HTML files hosted by the local CS web server, www.cs.swarthmore.edu. To use the SwatHtmlStream you must be logged into a Swarthmore Computer Science lab computer. You can use the SwatHtmlStream much like a file stream:
#include <iostream>
#include <string>
#include "swathtmlstream.h"
using namespace std;
int main(int argc, char** argv) {
SwatHtmlStream myFile("www.cs.swarthmore.edu/~charlie/index.html");
if (!myFile.good()) {
cerr << "Whoops! We couldn't open the url.\n";
return 1;
}
string word;
myFile >> word;
while (!myFile.eof()) {
cout << word << endl;
myFile >> word;
}
myFile.close();
return 0;
}
The SwatHtmlStream is not a fully-featured input stream, but can
read strings of words (and number-strings) from a given URL.
It skips HTML tags (for correctly-formatted HTML) and most punctuation
characters, and converts all strings to lowercase.
- In your home directory, make a public_html directory to
hold the web page, then make that directory readable and
executable for everyone:
$ mkdir ~/public_html $ chmod a+rx ~/public_html
- Inside your public_html directory make an index.html
file, then make that file readable by everyone:
$ chmod a+r ~/public_html/index.html
You can start with a simple text file (e.g., Hello world!) and add more to it later. (See other users' web pages for examples of what you can do in HTML.) - After you've saved your index.html file and made it world-readable, use a web browser to view: http://www.cs.swarthmore.edu/~yourUserName
Once you are satisfied with your program, hand it in by typing handin35 at the unix prompt.
You may run handin35 as many times as you like, and only the most recent submission will be recorded. This is useful if you realize after handing in some programs that you'd like to make a few more changes to them.