Reading 5, Part 2: Exceptions
Credits: This reading is a port from Java to C# from 6.005
— Software Construction on MIT OpenCourseWare . Click here
to see the original reading based on Java.
Now that we’re writing specifications and thinking about how clients will use our methods, let’s discuss how to handle exceptional cases in a way that is safe from bugs and easy to understand.
A method’s signature — its name, parameter types, return type — is a core part of its specification, and the signature may also include exceptions that the method may trigger.
Exceptions for signaling bugs
You’ve probably already seen some exceptions in your C# programming so far, such as
IndexOutOfRangeException
(thrown when an array index
foo[i]
is outside the valid range for the array
foo
) or
NullReferenceException
(thrown when trying to call a method on a
null
object reference).
These exceptions generally indicate
bugs
in your code, and the information displayed by C# when the exception is thrown can help you find and fix the bug. Usually, you will get a callstack which shows you the files and line numbers that led to the exception.
IndexOutOfRangeException
and
NullReferenceException
are probably the most common exceptions of this sort.
Other examples include:
-
ArithmeticException, which is the base class for errors such asDivideByZeroExceptionandOverflowException -
FormatException, thrown by methods likeInt64.Parseif you pass in a string that cannot be parsed into an integer.
Exceptions for special results
Exceptions are not just for signaling bugs. They can be used to improve the structure of code that involves procedures with special results.
An unfortunately common way to handle special results is to
return special values.
Lookup operations in the Java library are often designed like this: you
get an index of -1 when expecting a positive integer, or a
null
reference when expecting an object.
This approach is OK if used sparingly, but it has two problems.
First, it’s tedious to check the return value.
Second, it’s easy to forget to do it.
Also, it’s not always easy to find a ‘special value’.
Suppose we have a
BirthdayBook
class with a lookup method.
Here’s one possible method signature:
class BirthdayBook {
DateTime Lookup(string name) { ... }
}
(
DateTime
is part of the C# .NET API.)
What should the method do if the birthday book doesn’t have an entry for the person whose name is given? Well, we could return some special date that is not going to be used as a real date. Bad programmers have been doing this for decades; they would return 9/9/99, for example, since it was obvious that no program written in 1960 would still be running at the end of the century. ( They were wrong, by the way. )
Here’s another approach. The method throws an exception:
DateTime lookup(string name) {
...
if ( ...not found... )
throw new ObjectNotFoundException();
...
and the caller handles the exception with a
catch
clause.
For example:
BirthdayBook birthdays = ...
try {
DateTime birthdate = birthdays.Lookup("Alyssa");
// we know Alyssa's birthday
} catch (ObjectNotFoundException nfe) {
// her birthday was not in the birthday book
}Now there’s no need for any special value, nor the checking associated with it.
Read: Exceptions in the C# programming guide.
Read: Exceptions Best Practices in the C# programming guide.
C# only has support for unchecked exceptions. This means that the compiler does not enforce whether or not you handle an exception. This is a controversal deign decision. It follows that C# exceptions are really intended solely for signaling bugs or unusual input cases, rather than as a type of return value. Thus, if a situation is expected to be common, it's better to handle it inside your function without throwing and exception. Here is another way we can implement Lookup.
// requires: no special requirements
// effects: if the name is found, sets birthday to their birthday and returns true; otherwise returns false.
bool Lookup(string name, out DateTime birthday)
{
birthday = ...empty value
if (.... found ...)
{
birthday = ...lookup value
return true;
}
return false;
}
The above code has two post-conditions. And you would use it like so
DateTime birthday = new DateTime();
if (Lookup(name, out birthday))
... print happy birthday
NOTE: All exceptions may have an optional message associated with them. It's good practice to include a string that helps you identify the cause of the error!
if (n > 0)
throw new Exception("My custom message");
else
throw new Exception(); // empty message
Exception hierarchy
Exceptions are a special class of objects that represent errors that can occur at runtime.
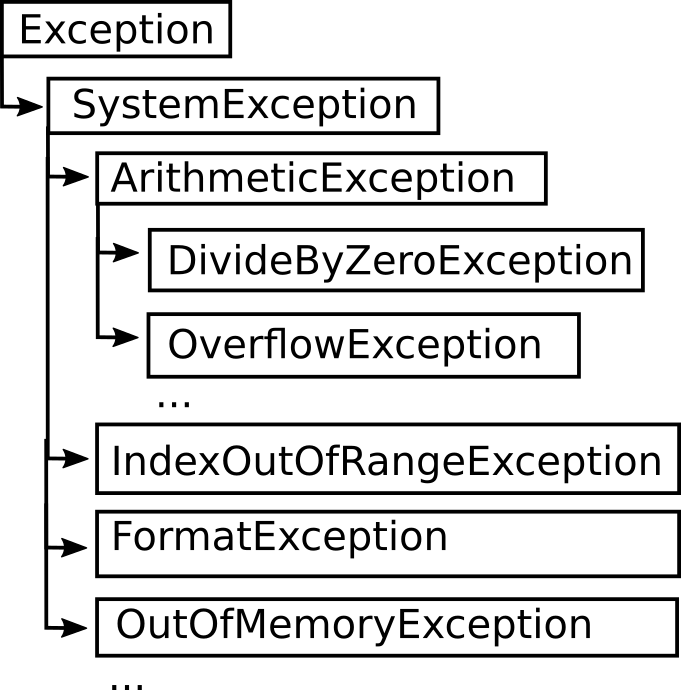
Exception
is the class of objects that can be thrown or caught.
Exception
’s implementation records a stack trace at the point where the
exception was thrown, along with an optional string describing the
exception.
Errors should be considered unrecoverable, and are generally not caught.
When throwing exceptions, you typically want to throw an existing exception, if it applies. When you define your own exceptions, you should either subclass
SystemException
or
Exception
You should try to recover from exceptions whenever possible -- particularly for errors that occur frequently as part of normal execution. For example, catch exceptions when attempting to open a file or read user input. If it's not possible for you to recover from an error, allow the exception to percolate up the callstack so that it may be handled at a higher level. Similarly, try to design classes so that exceptions are avoided.
You should also be mindful of what happens to the state of your objects when
an exception is thrown. generally, you will want to restore the state of
objects before throwing an error. You can use the using keyword to
automatically clean up resources derived from IDisposable. This is a great feature for
working with files and web streams for example.
using (WebClient wc = new WebClient())
{
return ReadTweets(wc.OpenRead(url));
}
Alternatively, you can cleanup resources in a finally block or before
re-throwing an exception. The following example is from Microsoft's
exception documentation
private static void TransferFunds(Account from, Account to, decimal amount)
{
string withdrawalTrxID = from.Withdrawal(amount);
try
{
to.Deposit(amount);
}
catch
{
from.RollbackTransaction(withdrawalTrxID);
throw;
}
}
Exception design considerations
For C#, the rule we have given is to use exceptions to signal bugs (unexpected failures). It's worthwhile to note that exceptions also incur a performance penalty. If it possible to avoid an exception with an inexpensive test, you should do so.
Here are some examples of applying this rule to hypothetical methods:
-
Queue.pop()throws anEmptyQueueExceptionwhen the queue is empty, but it’s reasonable to expect the caller to avoid this with a call likeQueue.size()orQueue.isEmpty(). -
Url.getWebPage()throws anIOExceptionwhen it can’t retrieve the web page. It’s not easy for the caller to prevent this, so we should put this code in a try...catch block. -
int integerSquareRoot(int x)throws aNotPerfectSquareExceptionwhenxhas no integral square root, because testing whetherxis a perfect square is just as hard as finding the actual square root, so it’s not reasonable to expect the caller to prevent it. This code should be in a try..catch block.
The cost of using exceptions is one reason that many API’s use the null reference as a special value. It’s not a terrible thing to do, so long as it’s done judiciously, and carefully specified.
Abuse of exceptions
Here’s an example from Effective Java by Joshua Bloch (Item 57 in the 2nd edition), converted into C#
try {
int i = 0;
while (true)
a[i++].f();
} catch (IndexOutOfRangeException e) { }What does this code do? It is not at all obvious from inspection, and that’s reason enough not to use it. … The infinite loop terminates by throwing, catching, and ignoring an
IndexOutOfRangeExceptionwhen it attempts to access the first array element outside the bounds of the array.
It is supposed to be equivalent to:
for (int i = 0; i < a.length; i++) {
a[i].f();
}
Or (using appropriate type
T
) to:
for (T x : a) {
x.f();
}The exception-based idiom, Bloch writes:
… is a misguided attempt to improve performance based on the faulty reasoning that, since the VM checks the bounds of array accesses, the normal loop termination test (
i < a.length) is redundant and should be avoided.
Considering Java: because exceptions in Java are designed for use only under exceptional circumstances, few, if any, JVM implementations attempt to optimize their performance. On a typical machine, the exception-based idiom runs 70 times slower than the standard one when looping from 0 to 99. This logic also applies to C# and C++: exceptions involve a lot of overhead and are incur a performance penalty.
Much worse than that, the exception-based idiom is not even guaranteed to work!
Suppose the computation of
f()
in the body of the loop contains a bug that results in an out-of-bounds access to some unrelated array.
What happens?
If a reasonable loop idiom were used, the bug would generate an uncaught exception, resulting in immediate thread termination with a full stack trace. If the misguided exception-based loop were used, the bug-related exception would be caught and misinterpreted as a normal loop termination.