1. Due Date
Due by 11:59 p.m., Friday, December 4, 2020.
Checkpoint: Wednesday, December 2 by noon.
Your lab partner for Lab 5 is listed here: Lab 5 lab partners
Our guidelines for working with partners: working with partners, etiquette and expectations
2. Overview
In this lab, you will create a relational movie database and pose a set of queries using SQLite. The raw data has been extracted from the Internet Movie Database (IMDb). You will structure this data in 6 tables to represent Movies, Actors, Directors, Genres, the relationship between director(s) for each movie (DirectsMovie), and the casts of each movie (Casts). Your schema is closely related to the following ER diagram:
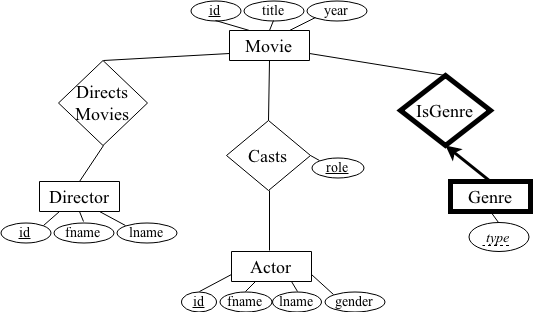
In addition, you will use embedded SQL to write a Python program to
interface with the sqlite3 engine. While there is a bit of a learning
curve to picking up the Python library for sqlite3, the SQL commands
are equivalent to those you would enter on the normal command-line
interface.
The objectives for your lab are:
-
to gain experience with one popular instance of a relational database (SQLite)
-
to combine procedural language (Python) elements with declarative language (SQL) constructs
-
to practice data definition language (DDL) commands in SQL
-
to design queries to answer questions about the data
-
to utilize indices and query planning to make your queries efficient
2.1. Getting Started
Find your git repo for this lab assignment off the GitHub server for our class: cs44-f20
Here are some detailed instructions on using git for CS44 labs.
Clone your git repo (Lab5-userID1-userID2) containing starting point files into your
labs directory:
cd ~/cs44/labs
git clone [the ssh url to your your repo]
cd Lab5-userID1-userID2If all was successful, you should see the following files (highlighted files require modification):
-
createDB.py- a main program for creating your initial database schema including the creation of tables and indices plus the insertion of records. You will only need to run this program one time once you get it working (but be sure to test it!) -
queryDB.py- the main user program. This program will prompt the user with a menu of all possible queries to run and execute the user’s choice(s) -
README.md- describe your indices as well as your free-design query.
In addition, you will utilize the following shared data files:
-
/home/soni/public/cs44/movieDB/- this folder contains the records to insert into your tables in the form ofrelationName.txt(e.g.,Casts.txtcontains all records of actors cast in a movie). DO NOT COPY THIS FOLDER - it will use up all of your disk quota.
You should utilize these references for using the sqlite library in Python:
-
SQLite API - a detailed description of the full library interface. This is a good reference for help on accomplishing specific tasks or inspecting data
-
Python tutorial - a quick-start guide for the basics of opening a database connection
-
Python Central tutorial guide - another quick-start guide
-
You can also do a web search on the specific topic. Start your search with "sqlite python"; e.g., how do I retrieve query results? Google: "sqlite python retrieve query results".
2.2. Checkpoint and Deliverables
As a soft checkpoint (this will not be graded), you should be done with
creating the relational database in createDB.py (i.e., defining all schemas
inserting all instances from the files) by the time your return from break
(Sunday, November 29).
The required checkpoint for lab on December 2 is as follows:
-
Complete
createTables() -
Complete
insertValues() -
Verify that all primary and foreign key constraints have been defined correctly
-
Complete the first three queries in
queryDB.py -
Define at least one index
The following will be evaluated for your lab grade:
-
queryDB.pyandcreateDB.py. Be sure your code compiles and runs efficiently. -
Describe your extension query and provide a justification for each of your indices in
README.md. -
Do not commit any other files than these three. Use
git rmif you mistakingly commit other files. -
Your Lab 5 Questionnaire to be completed individually (This will open on the due date and close after 3 days)
3. Creating the movie database
In createDB.py, place your code to create the movie database. You will
create tables, insert values into the table, and create indices on the
table as needed to solve your queries efficiently. The code has been
partially provided to help you get started. NOTE: do not use your home
directory to create the actual database - this will eat up your quota
very quickly. See our Tips for Performance
and Storage.
3.1. Schema
The schema is as follows:
-
Actor (id, fname, lname, gender)
-
Movie (id, title, year)
-
Director (id, fname, lname)
-
Casts (actorID, movieID, role)
-
DirectsMovie (directorID, movieID)
-
Genre (movieID, type)
Types
-
All
idfields are integers, as isyear. -
All other fields are character strings. You can use either
CHAR(N)orVARCHAR(N)for the character strings. -
Use a length of 30 characters for any
nameortitlefield -
Use a length of 50 characters for
roleandtype -
genderis a single character
Constraints
The primary keys are specified in italics above:
-
idis the key for Actor, Movie, and Director. -
For the remaining relations, the primary key is the combination of all attributes. This is because an actor can appear in a movie many times in different roles; each movie can fit multiple genres; and each movie can have multiple directors.
The foreign keys should be clear from the context:
-
Casts.actorID references Actor.id
-
Casts.movieID and DirectsMovie.movieID reference Movie.id.
-
DirectsMovie.directorID references Directors.id
The IMDb dataset is not perfectly clean and some entries in Genre.movieID refer to non-existing movies. This is the reality of "messy" data in the real world. In this instance, we drop the constraint rather than cleaning up the data. DO NOT specify that Genre.movieID is a foreign key.
You are responsible for making sure you meet the schema requirements. While some potential errors will be detected when you try insert values from the given files, primary key and foreign key constraints should be manually checked by you. Try inserting duplicate values to make sure they are rejected.
3.2. Provided methods
-
main()
This method has been provided for you; read it to understand the top-level design of the rest of the program. The program takes the name of the database file as a command-line argument, verifies the file exists, establishes a connect to the sqlite dbms, creates all tables and inserts values, and builds indices before exiting. -
checkDB()
Determines if the database already exists. If it does the user must choose between removing the database (starting from scratch), exiting (do nothing) or keep the existing database and only reconstruct indexes. This third option will come in handy when are designing your queries for the second part of the assignment. The methods returnsTrueif either the file did not exist or if the user choose to remove the existing file. The program returnsFalseif schemas and tuples should be kept and only indexes need to be reconstructed. -
dropIndexes()
Removes all existing indexes in the database. This is useful during query design when you experiment with the best indexes to construct for your queries.
3.3. Required methods
-
createTables()
Issues SQL commands to create all 6 tables in the schema. The first line of the given code turns referential integrity checks on. You will need to submit commands to thesqliteto define all table schemas. -
insertValues()
You may not use.importto import all values. Instead, you must read each file, parsing the arguments on each line, and insert the results one-by-one using theINSERT INTOSQL command. You may want to take a look atexecutemany()function to see how all insertions can be executed at one time. There are helpful examples here and here.Each relation’s text file contains one record per line. Fields are separated by
'|'delimiters, and are in the same order as the schemas above. If it has been awhile since you have done file parsing in Python, read this tutorial on file input. You should not need to worry about type casting since SQL should handle that. Note that in Python3, you may see encoding errors as some of the symbols are not utf-8 compatible. When opening the file, specify that errors can be modified:with open('/home/soni/public/cs44/movieDB/Actor.txt','r',errors="backslashreplace") as f: #process fileAdditionally, the order in which you insert tuples matters since the DB will check foreign key references. Insert relations with foreign key references after their referenced relations have been populated.
-
createIndex()
Place all SQL commands for creating indices here. You should choose your indices wisely. You will probably need to complete this function after solving some of the queries below. As an aside, most queries should run quickly (a few seconds at most). In theREADME.mdfile, you should provide a justification for each index constructed by citing which queries it is useful for. Each index must be justified (your grade depends on both building indices that improve run time as well as avoiding unnecessary indices). See the tips below for additional help. Also, note that SQLite automatically builds some indices (e.g., on primary keys) so pay attention to your query plans to see if SQLite is actually using the ones you specify (and drop it if it is not used).
You may add additional methods as needed (for example, to help with inserting). Each method must be commented and clear to follow. Please read about using multi-line strings below to avoid unreadable code.
4. Querying the database
In queryDB.py, you will define your queries and implement a user
interface for interacting with the database. Your main method should
establish a connection in a similar fashion as createDB.py: read the
name of the database from the command line, check to see if the file
exists (exit cleanly if it does not), establish a connection and cursor.
See the sample output to get an idea of how
the program should run.
Next, your program should repeatedly print a menu of options until the
user selects "Exit" as an option. The menu has been provided for you
in printMenu(). Please do not change this method. After the user
enters a choice, you should call the appropriate query.
4.1. Requirements
-
Each query should be defined in a function
queryXwhere X is the number below. For example the first query listed in the Queries table below should be defined in the methodquery1(). -
Your queries should be easy to read. Your SQL commands are sent as strings through the
executemethod. Since these queries can be long, entering them as a very long line will make them very hard to read. Instead, you should use Python’s multi-line string format (i.e.,"""Long string"""to create strings with line breaks that make your queries easy to parse). For example, to query the number of Directors named"Steven":command = """ SELECT COUNT(*) FROM Directors D WHERE D.name = 'Steven' """ db.execute(command) results = db.fetchall() -
Print out the results in a formatted manner. Use the
printResultsfunction we provide to help with this. -
Print out the query plan after each query. Use the
explainQuery()we provide to help with this. You can also do this in SQLite directly to help you develop your queries and indexes. To get the query plan prefixEXPLAIN QUERY PLANto the query:
-
Your SQL queries should be written so that they are run efficiently. SQLite will make use of indices if they exist. Try out queries in SQLite command line, look at the query plan, and think about re-structuring and adding indices to improve the performance of slow queries. Just because you define an index doesn’t mean it is useful. Be sure to check your query plans to see if the index is being utilized (see Tips below).
-
You should print out the time it takes to perform each query using the
timelibrary in Python:start = time.time() # execute query # call fetchall to get results end = time.time() print("\nCompleted in %.3f seconds" % (end-start)) # print resultsYou only need to count the execution time and fetching results, not the time to print your results or explain the query.
-
You are allowed to create temporary tables to store intermediate queries. But you must drop temporary tables as soon as you complete the query. For example, if you create a temporary table called
MyTable, remove it when you are done with the query by running:db.execute("DROP TABLE MyTable")
4.2. Queries
You will need to answer the following queries. Since there are many ways to write the same query, we ask that you sort your final results as specified to make comparisons easier. Queries 4-6 should be in descending order (largest values first) while others are ascending. "Additional attributes" are attributes that should appear in your results but are not relevant to the sort ordering.
| Query | Description | Sort attributes | Additional attributes to print |
|---|---|---|---|
1 |
List the names of all distinct actors in the movie "The Princess Bride" |
Actor’s first name, Actor’s last name |
|
2 |
Ask the user for the name of an actor, and print all the movies starring an actor with that name (only print each title once). |
Movie title |
|
3 |
Ask the user for the name of two actors. Print the names of all distinct movies in which those two actors co-starred (i.e., the movie starred both actors). |
Movie id |
Movie title |
4 |
List all directors who directed 500 movies or more, in descending order of the number of movies they directed. Include the director’s name and the number of movies they directed. |
Number of movies directed |
Director’s first name and last name |
5 |
Challenge Find Kevin Bacon’s favorite co-stars. Print all actors as well as the number of movies that actor has co-starred with Kevin Bacon (but only if they’ve acted together in 8 movies or more). Be sure that Kevin Bacon isn’t in your results! Only count each movie once per actor (i.e., ignore multiple roles in the same film) |
Number of distinct movies co-starred |
Co-stars first name and last name |
6 |
Find actors who played five or more roles in the same movie during the year 2010. |
Number of roles, Movie title |
Actor’s first name and last name |
7 |
Programmer’s Choice: develop your own query. It should be both meaningful and non-trivial - show off your relational reasoning skills! (But keep the query under a minute of run time) |
Query 5 is probably the most difficult. We recommend breaking it down into
smaller pieces and using temporary tables. See tips below for using CREATE
TABLE tempResult AS SELECT … to store the result of a query as a table.
4.3. Example Run
It is up to you to evaluate your query results for correctness and efficiency. We have provided sample output for some of the queries to help understand what your program should do. The output includes an estimate for the number of tuples queries will return, and the time it takes for my queries to run (see if you can beat my time!).
5. Tips and additional details
-
See this page for tips on where to store your data: Tips for Performance and Storage.
-
You will want to divorce SQL errors from Python errors as much as possible. Since SQL queries are roughly the same in both SQLite and the Python interface to SQLite, you should practice running your queries using the SQLite command-line interface. Note that a DB created using Python can be inspected by loading it up in SQLite. For example:
$ python createDB.py /local/me_n_pal/movie.db $ sqlite3 movie.db SQLite version 3.7.9 2011-11-01 00:52:41 Enter ".help" for instructions Enter SQL statements terminated with a ";" sqlite> .table .table Actor Casts DirectMovie Director Genre Movie sqlite>
-
This data set is pretty large.
createDB.pymay take awhile to insert all of the values and construct the indices (~10 minutes). Your queries, however, should run fairly quickly. -
When designing your indices, it will get tedious to do so in
createDB.pysince the insertion of records takes several minutes while constructing indices is quick. We suggest doing allDROP INDEXandCREATE INDEXoperations insqlite3orsqlitebrowseruntil you are satisfied. Keep track of which indices you want to keep and add them to yourcreateDB.pyscript (and be sure to test that you kept the correct ones!). -
Query taking a long time? Try breaking up the query into multiple pieces, saving intermediate results using the
CREATE TABLE name AS …syntax. Sqlite may not optimize nested queries well in certain cases, so if the nest is a static table, it may be faster to pre-calculate the table. -
In some cases, you might get a query closer to a minute depending on how you write the query. If your query is under a minute, you are probably fine. There is a fast (less than a second) solution for all of the queries. You are not required to fully optimize all queries, but you should avoid very poor performance on any individual query.
6. Submitting your lab
Before the due date, push your solution to github from one of your local repos to the GitHub remote repo.
From your local repo (in your ~/cs44/labs/Lab5-userID1-userID2 subdirectory)
make clean
git add *.py *.md # DO NOT DO git add *
git commit -m "my correct and well commented solution for grading"
git pushVerify that the results appear (e.g., by viewing the the repository on cs44-f20). You will receive deductions for submitting code that does not run or repos with merge conflicts. Also note that the time stamp of your final submission is used to verify late days, so please do not update your repo until after the late period has ended.
If that doesn’t work, take a look at the "Troubleshooting" section of the Using git for CS44 labs and the Using git pages. At this point, you should submit the required Lab 5 Questionnaire (each lab partner must do this).